Docs
About Apache OpenServerless
Apache OpenServerless is an Open Source project, released under the
Apache License
2.0
providing a portable and complete
Serverless
environment, allowing to build quickly and easily cloud-native
applications.
Our goal is to make OpenServerless ubitiquous, allowing it to easily
run a complete and portable environment that runs in every
Kubernetes.
OpenServerless is based on Apache
OpenWhisk, which provides a powerful,
production-ready serverless engine.
However, the serverless engine is just the beginning, because a
serverless environment requires a set of integrated services.
OpenServerless provides integrated with OpenWhisk several additional
services such as databases, object storage, and a cron scheduler.
Furthermore, we test it on many public cloud Kubernetes services and
on-premises Kubernetes vendors.
The platform is paired with a powerful CLI tool, ops, which lets you
deploy OpenServerless quickly and easily everywhere, and perform a lot
of development tasks.
Our goal is to build a complete distribution of a serverless
environment with the following features:
It is easy to install and manage.
Integrates all the key services to build applications.
It is as portable as possible to run potentially in every
Kubernetes.
It is however tested regularly against a set of supported Kubernetes
environments.
If you want to know more about our goals, check our
roadmap
document.
1 - Tutorial
Showcase serverless development in action
Tutorial
This tutorial walks you through developing a simple OpenServerless
application using the Command Line Interface (CLI) and Javascript (but
any supported language will do).
Its purpose is to showcase serverless development in action by creating
a contact form for a website. We will see the development process from
start to finish, including the deployment of the platform and running
the application.
1.1 - Getting started
Let’s start building a sample application
Getting started
Build a sample Application
Imagine we have a static website and need server logic to store contacts
and validate data. This would require a server, a database and some code
to glue it all together. With a serverless approach, we can just
sprinkle little functions (that we call actions) on top of our static
website and let OpenServerless take care of the rest. No more setting up
VMs, backend web servers, databases, etc.
In this tutorial, we will see how you can take advantage of several
services which are already part of a OpenServerless deployment and
develop a contact form page for users to fill it with their emails and
messages, which are then sent via email to us and stored in a database.
Openserverless CLI: Ops
Serverless development is mostly performed on the CLI, and
OpenServerless has its tool called ops. It’s a command line tool that
allows you to deploy (and interact with) the platform seamlessly to the
cloud, locally and in custom environments.
Ops is cross-platform and can be installed on Windows, Linux and MacOS.
You can find the project and the sources on
Apache OpenServerless Cli Github page
Deploy OpenServerless
To start using OpenServerless you can refer to the Installation
Guide. You can follow the local
installation to quickly get started with OpenServerless deployed on your
machine, or if you want to follow the tutorial on a deployment on cloud
you can pick one of the many supported cloud provider. Once installed
come back here!
Enabling Services
After installing OpenServerless on a local machine with Docker or on a
supported cloud, you can enable or disable the services offered by the platform.
As we will use Postgres database, the Static content with the Minio S3 compatible
storage and a cron scheduler, let’s run in the terminal:
ops config enable --postgres --static --minio --cron
Since you should already have a deployment running, we have to update it
with the new services so they get deployed. Simply run:
And with just that (when it finishes), we have everything we need ready
to use!
Cleaning Up
Once you are done and want to clean the services configuration, just
run:
ops config disable --postgres --static --minio --cron
1.2 - First steps
Move your first steps on Apache Openserverless
First steps
Starting at the Front
Right now, after a freshly installation, if we visit the <apihost> you
will see a very simple page with:
Welcome to OpenServerless static content distributor landing page!!!
That’s because we’ve activated the static content, and by default it
starts with this simple index.html page. We will instead have our own
index page that shows the users a contact form powered by OpenServerless
actions. Let’s write it now.
Let’s create a folder that will contain all of our app code:
contact_us_app.
Inside that create a new folder called web which will store our static
frontend, and add there a index.html file with the following:
<!DOCTYPE html>
<html>
<head>
<link href="//maxcdn.bootstrapcdn.com/bootstrap/3.3.0/css/bootstrap.min.css" rel="stylesheet" id="bootstrap-css">
</head>
<body>
<div id="container">
<div class="row">
<div class="col-md-8 col-md-offset-2">
<h4>Get in Touch</h4>
<form method="POST">
<div class="form-group">
<input type="text" name="name" class="form-control" placeholder="Name">
</div>
<div class="form-group">
<input type="email" name="email" class="form-control" placeholder="E-mail">
</div>
<div class="form-group">
<input type="tel" name="phone" class="form-control" placeholder="Phone">
</div>
<div class="form-group">
<textarea name="message" rows="3" class="form-control" placeholder="Message"></textarea>
</div>
<button class="btn btn-default" type="submit" name="button">
Send
</button>
</form>
</div>
</div>
</div>
</body>
</html>
Now we just have to upload it to our OpenServerless deployment. You
could upload it using something like curl with a PUT to where your
platform is deployed at, but there is an handy command that does it
automatically for all files in a folder:
Pass to ops web upload the path to folder where the index.html is
stored in (the web folder) and visit again <apihost>.
Now you should see the new index page:
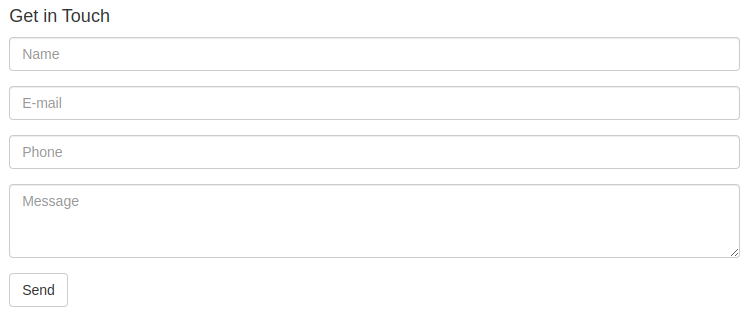
The contact form we just uploaded does not do anything. To make it work
let’s start by creating a new package to hold our actions. Moreover, we
can bind to this package the database url, so the actions can directly
access it!
With the debug command you can see what’s going on in your deployment.
This time let’s use it to grab the “postgres_url” value:
ops -config -d | grep POSTGRES_URL
Copy the Postgres URL (something like postgresql://...). Now we can
create a new package for the application:
ops package create contact -p dbUri <postgres_url>
ok: created package contact
The actions under this package will be able to access the “dbUri”
variable from their args!
To follow the same structure for our action files, let’s create a folder
packages and inside another folder contact to give our actions a
nice, easy to find, home.
To manage and check out your packages, you can use the ops packages
subcommands.
ops package list
packages
/openserverless/contact private
/openserverless/hello private <-- a default package created during deployment
And to get specific information on a package:
ops package get contact
ok: got package contact
{
"namespace": "openserverless",
"name": "contact",
"version": "0.0.1",
"publish": false,
"parameters": [
{
"key": "dbUri",
"value": <postgres_url>
}
],
"binding": {},
"updated": 1696232618540
}
1.3 - Form validation
Learn how to add form validation from front to back-end
Now that we have a contact form and a package for our actions, we have
to handle the submission. We can do that by adding a new action that
will be called when the form is submitted. Let’s create a submit.js
file in our packages/contact folder.
function main(args) {
let message = []
let errors = []
// TODO: Form Validation
// TODO: Returning the Result
}
This action is a bit more complex. It takes the input object (called
args) which will contain the form data (accessible via args.name,
args.email, etc.). With that. we will do some validation and then
return the result.
Validation
Let’s start filling out the “Form Validation” part by checking the name:
// validate the name
if(args.name) {
message.push("name: "+args.name)
} else {
errors.push("No name provided")
}
Then the email by using a regular expression:
// validate the email
var re = /\S+@\S+\.\S+/;
if(args.email && re.test(args.email)) {
message.push("email: "+args.email)
} else {
errors.push("Email missing or incorrect.")
}
The phone, by checking that it’s at least 10 digits:
// validate the phone
if(args.phone && args.phone.match(/\d/g).length >= 10) {
message.push("phone: "+args.phone)
} else {
errors.push("Phone number missing or incorrect.")
}
Finally, the message text, if present:
// validate the message
if(args.message) {
message.push("message:" +args.message)
}
Submission
With the validation phase, we added to the “errors” array all the errors
we found, and to the “message” array all the data we want to show to the
user. So if there are errors, we have to show them, otherwise, we store
the message and return a “thank you” page.
// return the result
if(errors.length) {
var errs = "<ul><li>"+errors.join("</li><li>")+"</li></ul>"
return {
body: "<h1>Errors!</h1>"+
errs + '<br><a href="javascript:window.history.back()">Back</a>'
}
} else {
var data = "<pre>"+message.join("\n")+"</pre>"
return {
body: "<h1>Thank you!</h1>"+ data,
name: args.name,
email: args.email,
phone: args.phone,
message: args.message
}
}
Note how this action is returning HTML code. Actions can return a
{ body: <html> } kind of response and have their own url so they can
be invoked via a browser and display some content.
The HTML code to display is always returned in the body field, but we
can also return other stuff. In this case we added a a field for each of
the form fields. This gives us the possibility to invoke in a sequence
another action that can act just on those fields to store the data in
the database.
Let’s start deploying the action:
ops action create contact/submit submit.js --web true
ok: created action contact/submit
The --web true specifies it is a web action. We are creating a
submit action in the contact package, that’s why we are passing
contact/submit.
You can retrieve the url with:
ops url contact/submit
$ <apihost>/api/v1/web/openserverless/contact/submit
If you click on it you will see the Error page with a list of errors,
that’s because we just invoked the submit logic for the contact form
directly, without passing in any args. This is meant to be used via the
contact form page!
We need to wire it into the index.html. So let’s open it again and add a
couple of attributes to the form:
--- <form method="POST"> <-- old
+++ <form method="POST" action="/api/v1/web/openserverless/contact/submit"
enctype="application/x-www-form-urlencoded"> <-- new
Upload the web folder again with the new changes:
ops web upload web/
Now if you go to the contact form page the send button should work. It
will invoke the submit action which in turn will return some html.
If you fill it correctly, you should see the “Thank you” page.
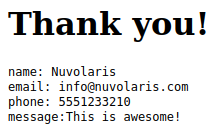
Note how only the HTML from the body field is displayed, the other
fields are ignored in this case.
The ops action command can be used for many more things besides
creating actions. For example, you can use it to list all available
actions:
ops action list
actions
/openserverless/contact/submit private nodejs:18
And you can also get info on a specific action:
ops action get contact/submit
{
"namespace": "openserverless/contact",
"name": "submit",
"version": "0.0.1",
"exec": {
"kind": "nodejs:18",
"binary": false
},
...
}
These commands can come in handy when you need to debug your actions.
Here is the complete the submit.js action:
function main(args) {
let message = []
let errors = []
// validate the name
if (args.name) {
message.push("name: " + args.name)
} else {
errors.push("No name provided")
}
// validate the email
var re = /\S+@\S+\.\S+/;
if (args.email && re.test(args.email)) {
message.push("email: " + args.email)
} else {
errors.push("Email missing or incorrect.")
}
// validate the phone
if (args.phone && args.phone.match(/\d/g).length >= 10) {
message.push("phone: " + args.phone)
} else {
errors.push("Phone number missing or incorrect.")
}
// validate the message
if (args.message) {
message.push("message:" + args.message)
}
// return the result
if (errors.length) {
var errs = "<ul><li>" + errors.join("</li><li>") + "</li></ul>"
return {
body: "<h1>Errors!</h1>" +
errs + '<br><a href="javascript:window.history.back()">Back</a>'
}
} else {
var data = "<pre>" + message.join("\n") + "</pre>"
return {
body: "<h1>Thank you!</h1>" + data,
name: args.name,
email: args.email,
phone: args.phone,
message: args.message
}
}
}
1.4 - Use database
Store data into a relational database
Use database
Storing the Message in the Database
We are ready to use the database that we enabled at the beginning of the
tutorial.
Since we are using a relational database, we need to create a table to
store the contact data. We can do that by creating a new action called
create-table.js in the packages/contact folder:
const { Client } = require('pg')
async function main(args) {
const client = new Client({ connectionString: args.dbUri });
const createTable = `
CREATE TABLE IF NOT EXISTS contacts (
id serial PRIMARY KEY,
name varchar(50),
email varchar(50),
phone varchar(50),
message varchar(300)
);
`
// Connect to database server
await client.connect();
console.log('Connected to database');
try {
await client.query(createTable);
console.log('Contact table created');
} catch (e) {
console.log(e);
throw e;
} finally {
client.end();
}
}
We just need to run this once, therefore it doesn’t need to be a web
action. Here we can take advantage of the cron service we enabled!
There are also a couple of console logs that we can check out.
With the cron scheduler you can annotate an action with 2 kinds of
labels. One to make OpenServerless periodically invoke the action, the
other to automatically execute an action once, on creation.
Let’s create the action with the latter, which means annotating the
action with autoexec true:
ops action create contact/create-table create-table.js -a autoexec true
ok: created action contact/create-table
With -a you can add “annotations” to an action. OpenServerless will
invoke this action as soon as possible, so we can go on.
In OpenServerless an action invocation is called an activation. You
can keep track, retrieve information and check logs from an action with
ops activation. For example, with:
You can retrieve the list of invocations. For caching reasons the first
time you run the command the list might be empty. Just run it again and
you will see the latest invocations (probably some hello actions from
the deployment).
If we want to make sure create-table was invoked, we can do it with
this command. The cron scheduler can take up to 1 minute to run an
autoexec action, so let’s wait a bit and run ops activation list
again.
ops activation list
Datetime Activation ID Kind Start Duration Status Entity
2023-10-02 09:52:01 1f02d3ef5c32493682d3ef5c32b936da nodejs:18 cold 312ms success openserverless/create-table:0.0.1
..
Or we could run ops activation poll to listen for new logs.
ops activation poll
Enter Ctrl-c to exit.
Polling for activation logs
When the logs from the create-table action appear, we can stop the
command with Ctrl-c.
Each activation has an Activation ID which can be used with other
ops activation subcommands or with the ops logs command.
We can also check out the logs with either ops logs <activation-id> or
ops logs --last to quickly grab the last activation’s logs:
ops logs --last
2023-10-15T14:41:01.230674546Z stdout: Connected to database
2023-10-15T14:41:01.238457338Z stdout: Contact table created
The Action to Store the Data
We could just write the code to insert data into the table in the
submit.js action, but it’s better to have a separate action for that.
Let’s create a new file called write.js in the packages/contact
folder:
const { Client } = require('pg')
async function main(args) {
const client = new Client({ connectionString: args.dbUri });
// Connect to database server
await client.connect();
const { name, email, phone, message } = args;
try {
let res = await client.query(
'INSERT INTO contacts(name,email,phone,message) VALUES($1,$2,$3,$4)',
[name, email, phone, message]
);
console.log(res);
} catch (e) {
console.log(e);
throw e;
} finally {
client.end();
}
return {
body: args.body,
name,
email,
phone,
message
};
}
Very similar to the create table action, but this time we are inserting
data into the table by passing the values as parameters. There is also a
console.log on the response in case we want to check some logs again.
Let’s deploy it:
ops action create contact/write write.js
ok: created action contact/write
Finalizing the Submit
Alright, we are almost done. We just need to create a pipeline of
submit → write actions. The submit action returns the 4 form
fields together with the HTML body. The write action expects those 4
fields to store them. Let’s put them together into a sequence:
ops action create contact/submit-write --sequence contact/submit,contact/write --web true
ok: created action contact/submit-write
With this command we created a new action called submit-write that is
a sequence of submit and write. This means that OpenServerless will
call in a sequence submit first, then get its output and use it as
input to call write.
Now the pipeline is complete, and we can test it by submitting the form
again. This time the data will be stored in the database.
Note that write passes on the HTML body so we can still see the thank
you message. If we want to hide it, we can just remove the body
property from the return value of write. We are still returning the
other 4 fields, so another action can use them (spoiler: it will happen
next chapter).
Let’s check out again the action list:
ops action list
actions
/openserverless/contact/submit-write private sequence
/openserverless/contact/write private nodejs:18
/openserverless/contact/create-table private nodejs:18
/openserverless/contact/submit private nodejs:18
You probably have something similar. Note the submit-write is managed as
an action, but it’s actually a sequence of 2 actions. This is a very
powerful feature of OpenServerless, as it allows you to create complex
pipelines of actions that can be managed as a single unit.
Trying the Sequence
As before, we have to update our index.html to use the new action.
First let’s get the URL of the submit-write action:
ops url contact/submit-write
<apihost>/api/v1/web/openserverless/contact/submit-write
Then we can update the index.html file:
--- <form method="POST" action="/api/v1/web/openserverless/contact/submit"
enctype="application/x-www-form-urlencoded"> <-- old
+++ <form method="POST" action="/api/v1/web/openserverless/contact/submit-write"
enctype="application/x-www-form-urlencoded"> <-- new
We just need to add -write to the action name.
Try again to fill the contact form (with correct data) and submit it.
This time the data will be stored in the database.
If you want to retrive info from you database, ops provides several
utilities under the ops devel command. They are useful to interact
with the integrated services, such as the database we are using.
For instance, let’s run:
ops devel psql sql "SELECT * FROM CONTACTS"
[{'id': 1, 'name': 'OpenServerless', 'email': 'info@nuvolaris.io', 'phone': '5551233210', 'message': 'This is awesome!'}]
1.5 - Sending notifications
Sending notifications on user interaction
Sending notifications
It would be great if we receive a notification when an user tries to
contact us. For this tutorial we will pick slack to receive a message
when it happens.
We need to:
have a slack workspace where we can send messages;
create a slack app that will be added to the workspace;
activate a webhook for the app that we can trigger from an action;
Check out the following scheme for the steps:
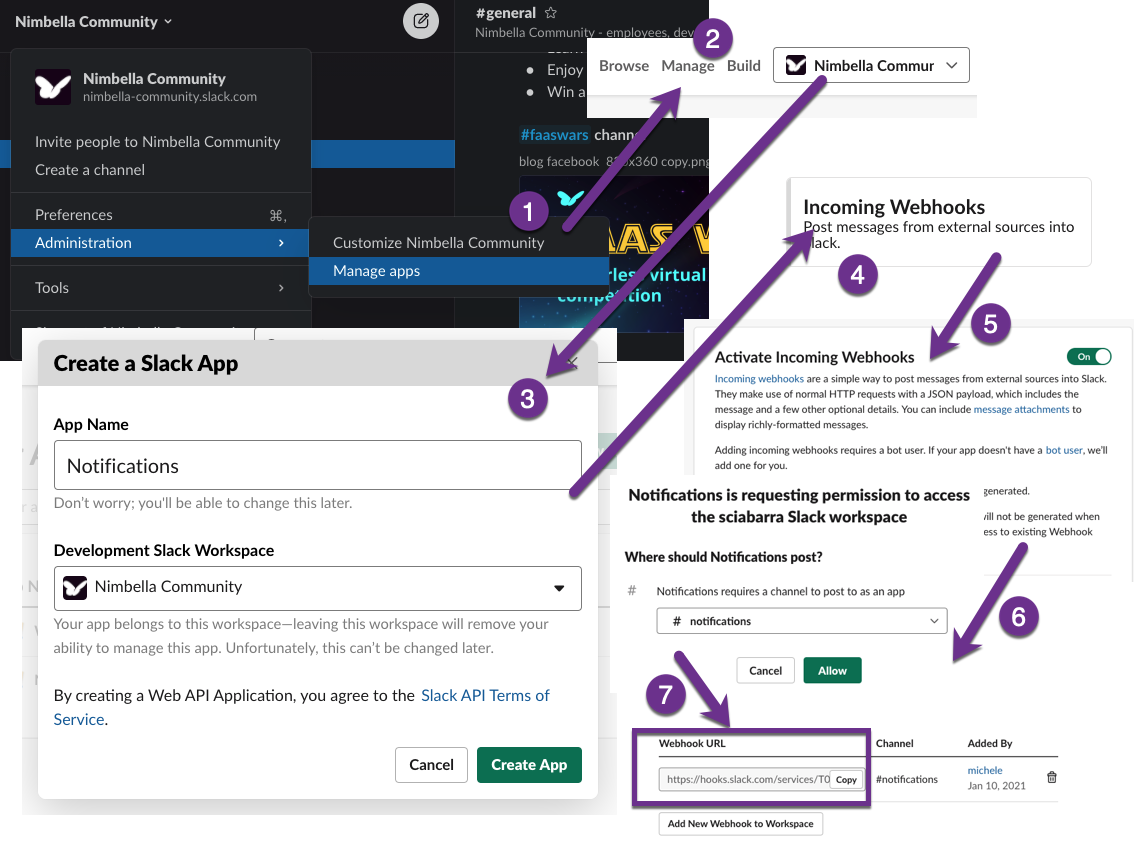
Once we have a webhook we can use to send messages we can proceed to
create a new action called notify.js (in the packages/contact
folder):
// notify.js
function main(args) {
const { name, email, phone, message } = args;
let text = `New contact request from ${name} (${email}, ${phone}):\n${message}`;
console.log("Built message", text);
return fetch(args.notifications, {
method: 'POST',
headers: {
'Content-Type': 'application/json',
},
body: JSON.stringify({ text }),
})
.then(response => {
if (!response.ok) {
console.log("Error sending message. Status code:", response.status);
} else {
console.log("Message sent successfully");
}
return {
body: args.body,
};
})
.catch(error => {
console.log("Error sending message", error);
return {
body: error,
};
});
}
This action has the args.notifications parameter, which is the
webhook. It also has the usual 4 form fields parameters that receives in
input, used to build the text of the message. The action will return the
body of the response from the webhook.
We’ve also put some logs that we can use for debugging purposes.
Let’s first set up the action:
ops action create contact/notify notify.js -p notifications <your webhook>
ok: created action contact/notify
We are already setting the notifications parameter on action creation,
which is the webhook. The other one is the text that the submit action
will give in input at every invocation.
Creating Another Action Sequence
We have developed an action that can send a Slack message as a
standalone action, but we designed it to take the output of the submit
action and return it as is. Time to extend the previous sequence!
Note that it will send messages for every submission, even for incorrect
inputs, so we will know if someone is trying to use the form without
providing all the information. But we will only store the fully
validated data in the database.
Let’s create the sequence, and then test it:
ops action create contact/submit-notify --sequence contact/submit-write,contact/notify --web true
ok: created action contact/submit-notify
We just created a new sequence submit-notify from the previous
sequence submit-write and the new notify.
If you want to get more info about this sequence, you can use the
ops action get command:
ops action get contact/submit-notify
{
"namespace": "openserverless/contact",
"name": "submit-notify",
"version": "0.0.1",
"exec": {
"kind": "sequence",
"components": [
"/openserverless/contact/submit-write",
"/openserverless/contact/notify"
]
},
...
}
See how the exec key has a kind of sequence and a list of
components that are the actions that compose the sequence.
Now to start using this sequence instead of using the submit action, we
need to update the web/index.html page to invoke the new sequence.
As before let’s grab the url:
ops url contact/submit-notify
<apihost>/api/v1/web/openserverless/contact/submit-notify
And update the index.html:
--- <form method="POST" action="/api/v1/web/openserverless/contact/submit-write"
enctype="application/x-www-form-urlencoded"> <-- old
+++ <form method="POST" action="/api/v1/web/openserverless/contact/submit-notify"
enctype="application/x-www-form-urlencoded"> <-- new
Don’t forget to re-upload the web folder with ops web upload web/.
Now try to fill out the form again and press send! It will execute the
sequence and you will receive the message from your Slack App.
The tutorial introduced you to some utilities to retrieve information
and to the concept of activation. Let’s use some more commands to
check out the logs and see if the message was really sent.
The easiest way to check for all the activations that happen in this app
with all their logs is:
ops activation poll
Enter Ctrl-c to exit.
Polling for activation logs
This command polls continuously for log messages. If you go ahead and
submit a message in the app, all the actions will show up here together
with their log messages.
To also check if there are some problems with your actions, run a couple
of times ops activation list and check the Status of the
activations. If you see some developer error or any other errors, just
grab the activation ID and run ops logs <activation ID>.
1.6 - App Deployment
Learn how to deploy your app on Apache Openserverless
App Deployment
Packaging the App
With OpenServerless you can write a manifest file (in YAML) to have an
easy way to deploy applications.
In this last chapter of the tutorial we will package the code to easily
deploy the app, both frontend and actions.
Start The Manifest File
Let’s create a “manifest.yaml” file in the packages directory which
will be used to describe the actions to deploy:
packages:
contact:
actions:
notify:
function: contacts/notify.js
web: true
inputs:
notifications:
value: $NOTIFICATIONS
This is the basic manifest file with just the notify action. At the
top level we have the standard packages keyword, under which we can
define the packages we want. Until now we created all of our actions in
the contact package so we add it under packages.
Then under each package, the actions keyword is needed so we can add
our action custom names with the path to the code (with function).
Finally we also add web: true which is equivalent to --web true when
creating the action manually.
Finally we used the inputs keyword to define the parameters to inject
in the function.
If we apply this manifest file (we will see how soon), it will be the
same as the previous
ops action create contact/notify <path-to-notify.js> -p notifications $NOTIFICATIONS --web true.
You need to have the webhooks url in the NOTIFICATIONS environment
variable.
The Submit Action
The submit action is quite straightforward:
packages:
contact:
actions:
...
submit:
function: contact/submit.js
web: true
The Database Actions
Similarly to the notify and submit actions, let’s add to the
manifest file the two actions for the database. We also need to pass as
a package parameter the DB url, so we will use inputs key as before,
but at the package level:
packages:
contact:
inputs:
dbUri:
type: string
value: $POSTGRES_URL
actions:
...
write:
function: contact/write.js
web: true
create-table:
function: contact/create-table.js
annotations:
autoexec: true
Note the create-table action does not have the web set to true as it
is not needed to be exposed to the world. Instead it just has the
annotation for cron scheduler.
The Sequences
Lastly, we created a sequence with submit and notify that we have to
specify it in the manifest file as well.
packages:
contact:
inputs:
...
actions:
...
sequences:
submit-write:
actions: submit, write
web: true
submit-notify:
actions: submit-write, notify
web: true
We just have to add the sequences key at the contact level (next to
actions) and define the sequences we want with the available actions.
Deployment
The final version of the manifest file is:
packages:
contact:
inputs:
dbUri:
type: string
value: $POSTGRES_URL
actions:
notify:
function: contact/notify.js
web: true
inputs:
notifications:
value: $NOTIFICATIONS
submit:
function: contact/submit.js
web: true
write:
function: contact/write.js
web: true
create-table:
function: contact/create-table.js
annotations:
autoexec: true
sequences:
submit-write:
actions: submit, write
web: true
submit-notify:
actions: submit-write, notify
web: true
ops comes equipped with a handy command to deploy an app:
ops project deploy.
It checks if there is a packages folder with inside a manifest file
and deploys all the specified actions. Then it checks if there is a
web folder and uploads it to the platform.
It does all what we did manually until now in one command.
So, from the top level directory of our app, let’s run (to also set the
input env var):
export POSTGRES_URL=<your-postgres-url>
export NOTIFICATIONS=<the-webhook>
ops project deploy
Packages and web directory present.
Success: Deployment completed successfully.
Found web directory. Uploading..
With just this command you deployed all the actions (and sequences) and
uploaded the frontend (from the web folder).
2 - CLI
An handy command line to interact with all parts of OpenServerless
OpenServerless CLI
The ops command is the command line interface to OpenServerless
It let’s you to install and manipulate the components of the system.
If it is not already included in the development environment provided
you can download the CLI suitable for your platform from here, and
install it
Login into the system
To start working with you have to login in some OpenServerless
installation.
The administrator should have provided with username, password and the
URL to access the system.
For example, let’s assume you are the user mirella and the system is
available on https://nuvolaris.dev.
In order to login type the following command and enter you password.
ops -login https://nuvolaris.dev mirella
Enter Password:
If the password is correct you are logged in the system and you can use
the commands described below.
Next Steps
Once logged in, you can:
2.1 - Entities
The parts that OpenServerless applications are made of
Entities
OpenServerless applications are composed by some “entities” that you can
manipulate either using a command line interface or programmatically
with code.
The command line interface is the ops command line tools, that can be
used directly on the command line or automated through scripts. You can
also a REST API crafted explicitly for OpenServerless.
The entities available in OpenServerless are:
Packages: They serve as a means of
grouping actions together, facilitating the sharing of parameters,
annotations, etc. Additionally, they offer a base URL that can be
utilized by web applications.
Actions: These are the fundamental
components of a OpenServerless application, capable of being written
in any programming language. Actions accept input and produce
output, both formatted in JSON.
Activations: Each action invocations
produces an activation id that can be listed. Action output and
results logged and are associated to activations and can be
retrieved providing an activativation id.
Sequences: Actions can be
interconnected, where the output of one action serves as the input
for another, effectively forming a sequence.
Triggers: Serving as entry points with
distinct names, triggers are instrumental in activating multiple
actions.
Rules: Rules establish an association
between a trigger and an action. Consequently, when a trigger is
fired, all associated actions are invoked accordingly.
The ops command
Let’s now provide an overview of OpenServerless’ command line interface,
focusing on the ops command.
The command can be dowloaded in precompile binary format for many
platform following the Download button on https://www.nuvolaris.io/
The ops command is composed of many commands, each one with many
subcommands. The general format is:
ops <entity> <command> <parameters> <flags>
Note that <parameters> and <flags> are different for each
<command>, and for each <entity> there are many subcommands.
The CLI shows documention in the form of help output if you do not
provide enough parameters to it. Start with ops to get the list of the
main commands. If you type the ops <entity> get the help for that
entity, and so on.
For example, let’s see ops output (showing the command) and the more
frequently used command, action, also showing the more common
subcommands, shared with many others:
$ ops
Welcome to Ops, the all-mighty OpenServerless Build Tool
The top level commands all have subcommands.
Just type ops <command> to see its subcommands.
Commands:
action work with actions
activation work with activations
invoke shorthand for action invoke (-r is the default)
logs shorthand for activation logs
package work with packages
result shorthand for activation result
rule work with rules
trigger work with triggers
url get the url of a web action$ wsk action
There are many more sub commands used for aministrative purposes. In
this documentation we only focus on the subcommands used to manage the
main entities of OpenServerless.
Keep in mind that commands represent entities, and their subcommands
follow the CRUD model (Create, Retrieve via get/list, Update, Delete).
This serves as a helpful mnemonic to understand the ops command’s
functionality. While there are exceptions, these will be addressed
throughout the chapter’s discussion. Note however that some subcommand
may have some specific flags.
Naming Entities
Let’s see how entities are named.
Each user also has a namespace, and everything a user creates,
belongs to it.
The namespace is usually created by a system administrator.
Under a namespace you can create triggers, rules, actions and packages.
Those entities will have a name like this:
/mirella/demo-triggger
/mirella/demo-rule
/mirella/demo-package
/mirella/demo-action
When you create a package, you can put under it actions and feeds. Those
entities are named
💡 NOTE
In the commands you do not require to specify a namespace. If your user
is mirella, your namespace is /mirella, and You type demo-package
to mean /mirella/demo-package, and demo-package/demo-action to mean
/mirella/demo-package/demo-action.
2.1.1 - Packages
How to group actions and their related files
Packages
OpenServerless groups actions and feeds in packages under a
namespace. It is conceptually similar to a folder containing a group of
related files.
A package allows you to:
Group related actions together.
Share parameters and annotations (each action sees the parameters
assigned to the package).
Provide web actions with a common prefix in the URL to invoke them.
For example, we can create a package demo-package and assign a
parameter:
$ ops package create demo-package -p email no-reply@nuvolaris.io
ok: created package demo-package
This command creates a new package with the specified name.
Package Creation, Update, and Deletion
Let’s proceed with the commands to list, get information, update, and
finally delete a package:
First, let’s list our packages:
$ ops package list
packages
/openserverless/demo-package/ private
If you want to update a package by adding a parameter:
$ ops package update demo-package -p email info@nuvolaris.io
ok: updated package demo-package
Let’s retrieve some package information:
$ ops package get demo-package -s
package /openserverless/demo-package/sample:
(parameters: *email)
Note the final -s, which means “summarize.”
Finally, let’s delete a package:
$ ops package delete demo-package
ok: deleted package demo-package
Adding Actions to the Package
Actions can be added to a package using this command:
ops action create <package-name>/<action-name>
This associates an existing action with the specified package.
Using Packages
Once a package is created, actions within it can be invoked using their
full path, with this schema: <package-name>/<action-name>. This allows
organizing actions hierarchically and avoiding naming conflicts.
Conclusion
Packages in OpenServerless provide a flexible and organized way to
manage actions and their dependencies. Using the Ops CLI, you can
efficiently create, add actions, and manage package dependencies,
simplifying the development and management of serverless applications.
2.1.2 - Actions
Functions, the core of OpenServerless
Actions
An action can generally be considered as a function, a snippet of code,
or generally a method.
The ops action command is designed for managing actions, featuring
frequently utilized CRUD operations such as list, create, update, and
delete. We will illustrate these operations through examples using a
basic hello action. Let’s assume we have the following file in the
current directory:
The hello.js script with the following content:
function main(args) {
return { body: "Hello" }
}
Simple Action Deployment
If we want to deploy this simple action in the package demo, let’s
execute:
$ ops package update demo
ok: updated package demo
$ ops action update demo/hello hello.js
ok: update action demo/hello
Note that we ensured the package exists before creating the action.
We can actually omit the package name. In this case, the package name is
default, which always exists in a namespace. However, we advise always
placing actions in some named package.
💡 NOTE
We used update, but we could have used create if the action does not
exist because update also creates the action if it does not exist and
updates it if it is already there. Update here is similar to the patch
concept in REST API. However, create generates an error if an action
does not exist, while update does not, so it is practical to always
use update instead of create (unless we really want an error for an
existing action for some reason).
How to Invoke Actions
Let’s try to run the action:
$ ops invoke demo/hello
{
"body": "Hello"
}
Actually, the invoke command does not exist, or better, it’s just a
handy shortcut for ops action invoke -r.
If you try to run ops action invoke demo/hello, you get:
$ ops action invoke demo/hello
ok: invoked /_/demo/hello with id fec047bc81ff40bc8047bc81ff10bc85
You may wonder where the result is. In reality, in OpenServerless, all
actions are by default asynchronous, so what you usually get is the
activation id to retrieve the result once the action is completed.
To block the execution until the action is completed and get the result,
you can either use the flag -r or --result, or use ops invoke.
Note, however, that we are using ops to invoke an action, which means
all the requests are authenticated. You cannot invoke actions directly
without logging into the system first.
However, you can mark an action to be public by creating it with
--web true (see below).
Public Actions
If you want an action to be public, you can do:
$ ops action update demo/hello hello.js --web true
ok: updated action demo/hello
$ ops url demo/hello
https://nuvolaris.dev/api/v1/web/mirella/demo/hello
and you can invoke it with:
$ curl -sL https://nuvolaris.dev/api/v1/web/dashboard/demo/hello
Hello
Note that the output is only showing the value of the body field. This
is because the web actions must follow a pattern to produce an output
suitable for web output, so the output should be under the key body,
and so on. Check the section on Web Actions for more information.
💡 NOTE
Actually, ops url is a shortcut for ops action get --url. You can
use ops action get to retrieve a more detailed description of an
action in JSON format.
After action create, action update, and action get (and the
shortcuts invoke and url), we should mention action list and
action delete.
The action list command obviously lists actions and allows us to
delete them:
$ ops action list
/mirella/demo/hello private nodejs:18
$ ops action delete demo/hello
ok: deleted action demo/hello
Conclusion
Actions are a core part of our entities. A ops action is a
self-contained and executable unit of code deployed on the ops
serverless computing platform.
2.1.3 - Activations
Detailed records of action executions
Activations
When an event occurs that triggers a function, ops creates an activation
record, which contains information about the function execution, such as
input parameters, output results, and any metadata associated with the
activation. It’s something similar to the classic concept of log.
How activations work
When invoking an action with ops action invoke, you’ll receive only an
invocation id as an answer.
This invocation id allows you to read results and outputs produced by
the execution of an action.
Let’s demonstrate how it works by modifying the hello.js file to add a
command to log some output.
function main(args) {
console.log("Hello")
return { "body": "Hello" }
}
Now, let’s deploy and invoke it (with a parameter hello=world) to get
the activation id:
$ ops action update demo/hello hello.js
ok: updated action demo/hello
$ ops action invoke demo/hello
ok: invoked /_/demo/hello with id 0367e39ba7c74268a7e39ba7c7126846
Associated with every invocation, there is an activation id (in the
example, it is 0367e39ba7c74268a7e39ba7c7126846).
We use this id to retrieve the results of the invocation with
ops activation result or its shortcut, just ops result, and we can
retrieve the logs using ops activation logs or just ops logs.
$ ops result 0367e39ba7c74268a7e39ba7c7126846
{
"body": "Hello"
}
$ ops logs 0367e39ba7c74268a7e39ba7c7126846
2024-02-17T20:01:31.901124753Z stdout: Hello
List of activations
You can list the activations with ops activation list and limit the
number with --limit if you are interested in a subset.
$ ops activation list --limit 5
Datetime Activation ID Kind Start Duration Status Entity
2024-02-17 20:01:31 0367e39ba7c74268a7e39ba7c7126846 nodejs:18 warm 8ms success dashboard/hello:0.0.1
2024-02-17 20:00:00 f4f82ee713444028b82ee71344b0287d nodejs:18 warm 5ms success dashboard/hello:0.0.1
2024-02-17 19:59:54 98d19fe130da4e93919fe130da7e93cb nodejs:18 cold 33ms success dashboard/hello:0.0.1
2024-02-17 17:40:53 f25e1f8bc24f4f269e1f8bc24f1f2681 python:3 warm 3ms success dashboard/index:0.0.2
2024-02-17 17:35:12 bed3213547cc4aed93213547cc8aed8e python:3 warm 2ms success dashboard/index:0.0.2
Note also the --since option, which is useful to show activations from
a given timestamp (you can obtain a timestamp with date +%s).
Since it can be quite annoying to keep track of the activation id, there
are two useful alternatives.
With ops result --last and ops logs --last, you can retrieve just
the last result or log.
Polling activations
With ops activation poll, the CLI starts a loop and displays all the
activations as they happen.
$ ops activation poll
Enter Ctrl-c to exit.
Polling for activation logs
Conclusion
Activations provide a way to monitor and track the execution of
functions, enabling understanding of how code behaves in response to
different events and allowing for debugging and optimizing serverless
applications.
2.1.4 - Sequences
Combine actions in sequences
Sequences
You can combine actions into sequences and invoke them as a single
action. Therefore, a sequence represents a logical junction between two
or more actions, where each action is invoked in a specific order.
Combine actions sequentially
Suppose we want to describe an algorithm for preparing a pizza. We could
prepare everything in a single action, creating it all in one go, from
preparing the dough to adding all the ingredients and cooking it.
What if you would like to edit only a specific part of your algorithm,
like adding fresh tomato instead of classic, or reducing the amount of
water in your pizza dough? Every time, you have to edit your main action
to modify only a part.
Again, what if before returning a pizza you’d like to invoke a new
action like “add basil,” or if you decide to refrigerate the pizza dough
after preparing it but before cooking it?
This is where sequences come into play.
Create a file called preparePizzaDough.js
function main(args) {
let persons = args.howManyPerson;
let flour = persons * 180; // grams
let water = persons * 120; // ml
let yeast = (flour + water) * 0.02;
let pizzaDough =
"Mix " +
flour +
" grams of flour with " +
water +
" ml of water and add " +
yeast +
" grams of brewer's yeast";
return {
pizzaDough: pizzaDough,
whichPizza: args.whichPizza,
};
}
Now, in a file cookPizza.js
function main(args) {
let pizzaDough = args.pizzaDough;
let whichPizza = args.whichPizza;
let baseIngredients = "tomato and mozzarella";
if (whichPizza === "Margherita") {
return {
result:
"Cook " +
pizzaDough +
" topped with " +
baseIngredients +
" for 3 minutes at 380°C",
};
} else if (whichPizza === "Sausage") {
baseIngredients += "plus sausage";
return {
result:
"Cook " +
pizzaDough +
" topped with " +
baseIngredients +
". Cook for 3 minutes at 380°C",
};
}
}
We have now split our code to prepare pizza into two different actions.
When we need to edit only one action without editing everything, we can
do it! Otherwise, we can now add new actions that can be invoked or not
before cooking pizza (or after).
Let’s try it.
Testing the sequence
First, create our two actions
ops action create preparePizzaDough preparePizzaDough.js
ops action create cookPizza cookPizza.js
Now, we can create the sequence:
ops action create pizzaSequence --sequence preparePizzaDough,cookPizza
Finally, let’s invoke it
ops action invoke --result pizzaSequence -p howManyPerson 4 -p whichPizza "Margherita"
{
"result": "Cook Mix 720 grams of flour with 480 ml of water and add 24 grams of brewer's yeast topped with tomato and mozzarella for 3 minutes at 380°C"
}
Conclusion
Now, thanks to sequences, our code is split correctly, and we are able
to scale it more easily!
2.1.5 - Triggers
Event source that triggers an action execution
Triggers
Now let’s see what a trigger is and how to use it.
We can define a trigger as an object representing an event source
that triggers the execution of actions. When activated by an event,
associated actions are executed.
In other words, a trigger is a mechanism that listens for specific
events or conditions and initiates actions in response to those events.
It acts as the starting point for a workflow.
Example: Sending Slack Notifications
Let’s consider a scenario where we want to send Slack notifications when
users visit specific pages and submit a contact form.
Step 1: Define the Trigger
We create a trigger named “PageVisitTrigger” that listens for events
related to user visits on our website. To create it, you can use the
following command:
ops trigger create PageVisitTrigger
Once the trigger is created, you can update it to add parameters, such
as the page parameter:
ops trigger update PageVisitTrigger --param page homepage
💡 NOTE
Of course, there are not only create and update, but also delete,
and they work as expected, updating and deleting triggers. In the next
paragraph, we will also see the fire command, which requires you to
first create rules to do something useful.
Step 2: Associate the Trigger with an Action
Next, we create an action named “SendSlackNotification” that sends a
notification to Slack when invoked. Then, we associate this action with
our “PageVisitTrigger” trigger, specifying that it should be triggered
when users visit certain pages.
To associate the trigger with an action, you can use the following
command:
ops rule create TriggerRule PageVisitTrigger SendSlackNotification
We’ll have a better understanding of this aspect in
Rules
In this example, whenever a user visits either the homepage or the
contact page, the “SendSlackNotification” action will be triggered,
resulting in a Slack notification being sent.
Conclusion
Triggers provide a flexible and scalable way to automate workflows based
on various events. By defining triggers and associating them with
actions, you can create powerful applications that respond dynamically
to user interactions, system events, or any other specified conditions.
2.1.6 - Rules
Connection rules between triggers and actions
Rules
Once we have a trigger and some actions, we can create rules for the
trigger. A rule connects the trigger with an action, so if you fire the
trigger, it will invoke the action. Let’s see this in practice in the
next listing.
Create data
First of all, create a file called alert.js.
function main() {
console.log("Suspicious activity!");
return {
result: "Suspicious activity!"
};
}
Then, create a OpenServerless action for this file:
ops action create alert alert.js
Now, create a trigger that we’ll call notifyAlert:
ops trigger create notifyAlert
Now, all is ready, and now we can create our rule! The syntax follows
this pattern: “ops rule create {ruleName} {triggerName} {actionName}”.
ops rule create alertRule notifyAlert alert
Test your rule
Our environment can now be alerted if something suspicious occurs!
Before starting, let’s open another terminal window and enable polling
(with the command ops activation poll) to see what happens.
$ ops activation poll
Enter Ctrl-c to exit.
Polling for activation logs
It’s time to fire the trigger!
$ ops trigger fire notifyAlert
ok: triggered /notifyAlert with id 86b8d33f64b845f8b8d33f64b8f5f887
Now, go to see the result! Check the terminal where you are polling
activations now!
Enter Ctrl-c to exit.
Polling for activation logs
Activation: 'alert' (dfb43932d304483db43932d304383dcf)
[
"2024-02-20T03:15.15472494535Z stdout: Suspicious activity!"
]
Conclusion
💡 NOTE
As with all the other commands, you can execute list, update, and
delete by name.
A trigger can enable multiple rules, so firing one trigger actually
activates multiple actions. Rules can also be enabled and disabled
without removing them. As in the last example, let’s try to disable the
first rule and fire the trigger again to see what happens.
$ ops rule disable alertRule
ok: disabled rule alertRule
$ ops trigger fire notifyAlert
ok: triggered /_/notifyAlert with id 0f4fa69d910f4c738fa69d910f9c73af
In the activation polling window, we can see that no action is executed
now. Of course, we can enable the rule again with:
ops rule enable alertRule
2.2 - Administration
System administration
Administration
If you are the administrator and you have access to the Kubernetes
cluster where OpenServerless is
installed you can administer the
system.
You have access to the ops admin subcommand with the following
synopsis:
Subcommand: ops admin
Usage:
admin adduser <username> <email> <password> [--all] [--redis] [--mongodb] [--minio] [--postgres] [--storagequota=<quota>|auto]
admin deleteuser <username>
Commands:
admin adduser create a new user in OpenServerless with the username, email and password provided
admin deleteuser delete a user from the OpenServerless installation via the username provided
Options:
--all enable all services
--redis enable redis
--mongodb enable mongodb
--minio enable minio
--postgres enable postgres
--storagequota=<quota>
2.3 - Debugging
Utilities to troubleshoot OpenServerless’ cluster
The ops debug subcomand gives access to many useful debugging
utilities as follow:
You need access to the Kubernetes cluster where OpenServerless is
installed.
ops debug: available subcommands:
* apihost: show current apihost
* certs: show certificates
* config: show deployed configuration
* images: show current images
* ingress: show ingresses
* kube: kubernetes support subcommand prefix
* lb: show ingress load balancer
* log: show logs
* route: show openshift route
* runtimes: show runtimes
* status: show deployment status
* watch: watch nodes and pod deployment
* operator:version: show operator versions
The ops debug kube subcommand also gives detailed informations about
the underlying Kubernetes cluster:
ops debug kube: available subcommands:
* ctl: execute a kubectl command, specify with CMD=<command>
* detect: detect the kind of kubernetes we are using
* exec: exec bash in pod P=...
* info: show info
* nodes: show nodes
* ns: show namespaces
* operator: describe operator
* pod: show pods and related
* svc: show services, routes and ingresses
* users: show openserverless users custom resources
* wait: wait for a value matching the given jsonpath on the specific resources under the namespace openserverless
2.4 - Project
How to deal with OpenServerless projects
Project
An OpenServerless Project
⚠️ WARNING
This document is still 🚧 work in progress 🚧
A project represents a logical unit of functionality whose boundaries
are up to you. Your app can contain one or more projects. The folder
structure of a project determines how the deployer finds and labels
packages and actions, how it deploys static web content, and what it
ignores.
You can detect and load entire projects into OpenServerless with a
single command using the ops CLI tool.
Project Detection
When deploying a project, ops checks in the given path for 2 special
folders:
The packages folder: contains sub-folders that are treated as
OpenServerless packages and are assumed to contain actions in the
form of either files or folders, which we refer to as Single File
Actions (SFA) and Multi File Actions (MFA).
The web folder: contains static web content.
Anything else is ignored. This lets you store things in the root folder
that are not meant to be deployed on OpenServerless (such as build
folders and project documentation).
Single File Actions
A single file action is simply a file with specific extension (the
supported ones: .js .py .php .go .java), whici is directly deployed
as an action.
Multi File Actions
A multi-file action is a folder containing a main file and
dependencies. The folder is bundled into a zip file and deployed as an
action.
2.5 - Web Assets
How to handle frontend deployment
Upload Web Assets
The web folder in the root of a project is used to deploy static
frontends. A static front-end is a collection of static asset under a
given folder that will be published in a web server under a path.
Every uses has associated a web accessible static area where you can
upload static assets.
You can upload a folder in this web area with
ops web upload <folder>
Synopsis:
Subcommand: ops web
Commands to upload and manage static content.
Usage:
web upload <folder> [--quiet] [--clean]
Commands:
upload <folder> Uploads a folder to the web bucket in OpenServerless.
Options:
--quiet Do not print anything to stdout.
--clean Remove all files from the web bucket instead.
3 - Reference
OpenServerless Developer Guide
Welcome to OpenServerless Developer guide.
OpenServerless is based on Apache OpenWhisk
and the documentation in this section is derived for the official
OpenWhisk documentation.
In this sections we mostly document how to write actions
(functions), the building blocks of OpenWhisk and
OpenServerless applications. There are also a few related entities for
managing actions (packages, parameters etc) you also need to know.
You can write actions in a number of programming languages. OpenServerless
supports directly this list of programming
languages. The list is expanding over the time.
See below for documentation related to:
There is also a tutorial and a development
kit to build your own runtime for your
favorite programming language.
3.1 - Entities
In this section you can find more informations about OpenServerless and OpenWhisk entities.
3.1.1 - Actions
What Actions are and how to create and execute them
Actions
Actions are stateless functions that run on the OpenWhisk and
OpenServerless platform. For example, an action can be used to detect
the faces in an image, respond to a database change, respond to an API
call, or post a Tweet. In general, an action is invoked in response to
an event and produces some observable output.
An action may be created from a function programmed using a number of
supported languages and runtimes, or from a
binary-compatible executable.
While the actual function code will be specific to a language and
runtime, the operations to
create, invoke and manage an action are the same regardless of the
implementation choice.
We recommend that you review the cli and read
the tutorial before moving on to advanced
topics.
What you need to know about actions
Functions should be stateless, or idempotent. While the system
does not enforce this property, there is no guarantee that any state
maintained by an action will be available across invocations. In
some cases, deliberately leaking state across invocations may be
advantageous for performance, but also exposes some risks.
An action executes in a sandboxed environment, namely a container.
At any given time, a single activation will execute inside the
container. Subsequent invocations of the same action may reuse a
previous container, and there may exist more than one container at
any given time, each having its own state.
Invocations of an action are not ordered. If the user invokes an
action twice from the command line or the REST API, the second
invocation might run before the first. If the actions have side
effects, they might be observed in any order.
There is no guarantee that actions will execute atomically. Two
actions can run concurrently and their side effects can be
interleaved. OpenWhisk and OpenServerless does not ensure any
particular concurrent consistency model for side effects. Any
concurrency side effects will be implementation-dependent.
Actions have two phases: an initialization phase, and a run phase.
During initialization, the function is loaded and prepared for
execution. The run phase receives the action parameters provided at
invocation time. Initialization is skipped if an action is
dispatched to a previously initialized container — this is referred
to as a warm start. You can tell if an invocation was a warm
activation or a cold one requiring initialization by inspecting the
activation record.
An action runs for a bounded amount of time. This limit can be
configured per action, and applies to both the initialization and
the execution separately. If the action time limit is exceeded
during the initialization or run phase, the activation’s response
status is action developer error.
Accessing action metadata within the action body
The action environment contains several properties that are specific to
the running action. These allow the action to programmatically work with
OpenWhisk and OpenServerless assets via the REST API, or set an internal
alarm when the action is about to use up its allotted time budget. The
properties are accessible via the system environment for all supported
runtimes: Node.js, Python, Swift, Java and Docker actions when using the
OpenWhisk and OpenServerless Docker skeleton.
__OW_API_HOST the API host for the OpenWhisk and OpenServerless
deployment running this action.
__OW_API_KEY the API key for the subject invoking the action, this
key may be a restricted API key. This property is absent unless
requested with the annotation explicitly
provide-api-key
__OW_NAMESPACE the namespace for the activation (this may not be
the same as the namespace for the action).
__OW_ACTION_NAME the fully qualified name of the running action.
__OW_ACTION_VERSION the internal version number of the running
action.
__OW_ACTIVATION_ID the activation id for this running action
instance.
__OW_DEADLINE the approximate time when this action will have
consumed its entire duration quota (measured in epoch milliseconds).
3.1.2 - Web Actions
Actions annotated to quickly build web based applications
What web actions are
Web actions are OpenWhisk and OpenServerless actions annotated to quickly
enable you to build web based applications. This allows you to program
backend logic which your web application can access anonymously without
requiring an OpenWhisk and OpenServerless authentication key. It is up to the
action developer to implement their own desired authentication and
authorization (i.e.OAuth flow).
Web action activations will be associated with the user that created the
action. This actions defers the cost of an action activation from the
caller to the owner of the action.
Let’s take the following JavaScript action hello.js,
$ cat hello.js
function main({name}) {
var msg = 'you did not tell me who you are.';
if (name) {
msg = `hello ${name}!`
}
return {body: `<html><body><h3>${msg}</h3></body></html>`}
}
You may create a web action hello in the package demo for the
namespace guest using the CLI’s --web flag with a value of true or
yes:
$ ops package create demo
ok: created package demo
$ ops action create demo/hello hello.js --web true
ok: created action demo/hello
$ ops action get demo/hello --url
ok: got action hello
https://${APIHOST}/api/v1/web/guest/demo/hello
Using the --web flag with a value of true or yes allows an action
to be accessible via REST interface without the need for credentials. A
web action can be invoked using a URL that is structured as follows:
https://{APIHOST}/api/v1/web/{QUALIFIED ACTION NAME}.{EXT}`
The fully qualified name of an action consists of three parts: the
namespace, the package name, and the action name.
The fully qualified name of the action must include its package name,
which is default if the action is not in a named package.
An example is guest/demo/hello. The last part of the URI called the
extension which is typically .http although other values are
permitted as described later. The web action API path may be used with
curl or wget without an API key. It may even be entered directly in
your browser.
Try opening:
https://${APIHOST}/api/v1/web/guest/demo/hello.http?name=Jane
in your web browser. Or try invoking the action via curl:
curl https://${APIHOST}/api/v1/web/guest/demo/hello.http?name=Jane
Here is an example of a web action that performs an HTTP redirect:
function main() {
return {
headers: { location: 'http://openwhisk.org' },
statusCode: 302
}
}
Or sets a cookie:
function main() {
return {
headers: {
'Set-Cookie': 'UserID=Jane; Max-Age=3600; Version=',
'Content-Type': 'text/html'
},
statusCode: 200,
body: '<html><body><h3>hello</h3></body></html>' }
}
Or sets multiple cookies:
function main() {
return {
headers: {
'Set-Cookie': [
'UserID=Jane; Max-Age=3600; Version=',
'SessionID=asdfgh123456; Path = /'
],
'Content-Type': 'text/html'
},
statusCode: 200,
body: '<html><body><h3>hello</h3></body></html>' }
}
Or returns an image/png:
function main() {
let png = <base 64 encoded string>
return { headers: { 'Content-Type': 'image/png' },
statusCode: 200,
body: png };
}
Or returns application/json:
function main(params) {
return {
statusCode: 200,
headers: { 'Content-Type': 'application/json' },
body: params
};
}
The default content-type for an HTTP response is application/json and
the body may be any allowed JSON value. The default content-type may be
omitted from the headers.
It is important to be aware of the response size
limit for actions since a response that exceeds the
predefined system limits will fail. Large objects should not be sent
inline through OpenWhisk and OpenServerless, but instead deferred to an
object store, for example.
Handling HTTP requests with actions
An OpenWhisk and OpenServerless action that is not a web action requires both
authentication and must respond with a JSON object. In contrast, web
actions may be invoked without authentication, and may be used to
implement HTTP handlers that respond with headers, statusCode, and
body content of different types. The web action must still return a
JSON object, but the OpenWhisk and OpenServerless system (namely the
controller) will treat a web action differently if its result includes
one or more of the following as top level JSON properties:
headers: a JSON object where the keys are header-names and the
values are string, number, or boolean values for those headers
(default is no headers). To send multiple values for a single
header, the header’s value should be a JSON array of values.
statusCode: a valid HTTP status code (default is 200 OK if body is
not empty otherwise 204 No Content).
body: a string which is either plain text, JSON object or array,
or a base64 encoded string for binary data (default is empty
response).
The body is considered empty if it is null, the empty string "" or
undefined.
The controller will pass along the action-specified headers, if any, to
the HTTP client when terminating the request/response. Similarly the
controller will respond with the given status code when present. Lastly,
the body is passed along as the body of the response. If a
content-type header is not declared in the action result’s headers,
the body is interpreted as application/json for non-string values, and
text/html otherwise. When the content-type is defined, the
controller will determine if the response is binary data or plain text
and decode the string using a base64 decoder as needed. Should the body
fail to decoded correctly, an error is returned to the caller.
HTTP Context
All web actions, when invoked, receives additional HTTP request details
as parameters to the action input argument. They are:
__ow_method (type: string): the HTTP method of the request.
__ow_headers (type: map string to string): the request headers.
__ow_path (type: string): the unmatched path of the request
(matching stops after consuming the action extension).
__ow_user (type: string): the namespace identifying the OpenWhisk
and OpenServerless authenticated subject.
__ow_body (type: string): the request body entity, as a base64
encoded string when content is binary or JSON object/array, or plain
string otherwise.
__ow_query (type: string): the query parameters from the request
as an unparsed string.
A request may not override any of the named __ow_ parameters above;
doing so will result in a failed request with status equal to 400 Bad
Request.
The __ow_user is only present when the web action is annotated to
require authentication
and allows a web action to implement its own authorization policy. The
__ow_query is available only when a web action elects to handle the
“raw” HTTP request. It is a string containing the
query parameters parsed from the URI (separated by &). The __ow_body
property is present either when handling “raw” HTTP requests, or when
the HTTP request entity is not a JSON object or form data. Web actions
otherwise receive query and body parameters as first class properties in
the action arguments with body parameters taking precedence over query
parameters, which in turn take precedence over action and package
parameters.
Additional features
Web actions bring some additional features that include:
Content extensions: the request must specify its desired content
type as one of.json,.html,.http, .svg or .text. This is
done by adding an extension to the action name in the URI, so that
an action /guest/demo/hello is referenced as
/guest/demo/hello.http for example to receive an HTTP response
back. For convenience, the .http extension is assumed when no
extension is detected.
Query and body parameters as input: the action receives query
parameters as well as parameters in the request body. The precedence
order for merging parameters is: package parameters, binding
parameters, action parameters, query parameter, body parameters with
each of these overriding any previous values in case of overlap . As
an example /guest/demo/hello.http?name=Jane will pass the argument
{name: "Jane"} to the action.
Form data: in addition to the standard application/json, web
actions may receive URL encoded from data
application/x-www-form-urlencoded data as input.
Activation via multiple HTTP verbs: a web action may be invoked
via any of these HTTP methods: GET, POST, PUT, PATCH, and
DELETE, as well as HEAD and OPTIONS.
Non JSON body and raw HTTP entity handling: A web action may
accept an HTTP request body other than a JSON object, and may elect
to always receive such values as opaque values (plain text when not
binary, or base64 encoded string otherwise).
The example below briefly sketches how you might use these features in a
web action. Consider an action /guest/demo/hello with the following
body:
function main(params) {
return { response: params };
}
This is an example of invoking the web action using the .json
extension, indicating a JSON response.
$ curl https://${APIHOST}/api/v1/web/guest/demo/hello.json
{
"response": {
"__ow_method": "get",
"__ow_headers": {
"accept": "*/*",
"connection": "close",
"host": "172.17.0.1",
"user-agent": "curl/7.43.0"
},
"__ow_path": ""
}
}
You can supply query parameters.
$ curl https://${APIHOST}/api/v1/web/guest/demo/hello.json?name=Jane
{
"response": {
"name": "Jane",
"__ow_method": "get",
"__ow_headers": {
"accept": "*/*",
"connection": "close",
"host": "172.17.0.1",
"user-agent": "curl/7.43.0"
},
"__ow_path": ""
}
}
You may use form data as input.
$ curl https://${APIHOST}/api/v1/web/guest/demo/hello.json -d "name":"Jane"
{
"response": {
"name": "Jane",
"__ow_method": "post",
"__ow_headers": {
"accept": "*/*",
"connection": "close",
"content-length": "10",
"content-type": "application/x-www-form-urlencoded",
"host": "172.17.0.1",
"user-agent": "curl/7.43.0"
},
"__ow_path": ""
}
}
You may also invoke the action with a JSON object.
$ curl https://${APIHOST}/api/v1/web/guest/demo/hello.json -H 'Content-Type: application/json' -d '{"name":"Jane"}'
{
"response": {
"name": "Jane",
"__ow_method": "post",
"__ow_headers": {
"accept": "*/*",
"connection": "close",
"content-length": "15",
"content-type": "application/json",
"host": "172.17.0.1",
"user-agent": "curl/7.43.0"
},
"__ow_path": ""
}
}
You see above that for convenience, query parameters, form data, and
JSON object body entities are all treated as dictionaries, and their
values are directly accessible as action input properties. This is not
the case for web actions which opt to instead handle HTTP request
entities more directly, or when the web action receives an entity that
is not a JSON object.
Here is an example of using a “text” content-type with the same example
shown above.
$ curl https://${APIHOST}/api/v1/web/guest/demo/hello.json -H 'Content-Type: text/plain' -d "Jane"
{
"response": {
"__ow_method": "post",
"__ow_headers": {
"accept": "*/*",
"connection": "close",
"content-length": "4",
"content-type": "text/plain",
"host": "172.17.0.1",
"user-agent": "curl/7.43.0"
},
"__ow_path": "",
"__ow_body": "Jane"
}
}
Content extensions
A content extension is generally required when invoking a web action;
the absence of an extension assumes .http as the default. The fully
qualified name of the action must include its package name, which is
default if the action is not in a named package.
Protected parameters
Action parameters are protected and treated as immutable. Parameters are
automatically finalized when enabling web actions.
$ ops action create /guest/demo/hello hello.js \
--parameter name Jane \
--web true
The result of these changes is that the name is bound to Jane and
may not be overridden by query or body parameters because of the final
annotation. This secures the action against query or body parameters
that try to change this value whether by accident or intentionally.
Securing web actions
By default, a web action can be invoked by anyone having the web
action’s invocation URL. Use the require-whisk-auth web action
annotation to
secure the web action. When the require-whisk-auth annotation is set
to true, the action will authenticate the invocation request’s Basic
Authorization credentials to confirm they represent a valid OpenWhisk
and OpenServerless identity. When set to a number or a case-sensitive string,
the action’s invocation request must include a X-Require-Whisk-Auth
header having this same value. Secured web actions will return a
Not Authorized when credential validation fails.
Alternatively, use the --web-secure flag to automatically set the
require-whisk-auth annotation. When set to true a random number is
generated as the require-whisk-auth annotation value. When set to
false the require-whisk-auth annotation is removed. When set to any
other value, that value is used as the require-whisk-auth annotation
value.
ops action update /guest/demo/hello hello.js --web true --web-secure my-secret
or
ops action update /guest/demo/hello hello.js --web true -a require-whisk-auth my-secret
curl https://${APIHOST}/api/v1/web/guest/demo/hello.json?name=Jane -X GET -H "X-Require-Whisk-Auth: my-secret"
It’s important to note that the owner of the web action owns all of the
web action’s activations records and will incur the cost of running the
action in the system regardless of how the action was invoked.
Disabling web actions
To disable a web action from being invoked via web API
(https://APIHOST/api/v1/web/), pass a value of false or no to the
--web flag while updating an action with the CLI.
ops action update /guest/demo/hello hello.js --web false
Raw HTTP handling
A web action may elect to interpret and process an incoming HTTP body
directly, without the promotion of a JSON object to first class
properties available to the action input (e.g., args.name vs parsing
args.__ow_query). This is done via a raw-http
annotation. Using the same example show earlier,
but now as a “raw” HTTP web action receiving name both as a query
parameters and as JSON value in the HTTP request body:
$ curl https://${APIHOST}/api/v1/web/guest/demo/hello.json?name=Jane -X POST -H "Content-Type: application/json" -d '{"name":"Jane"}'
{
"response": {
"__ow_method": "post",
"__ow_query": "name=Jane",
"__ow_body": "eyJuYW1lIjoiSmFuZSJ9",
"__ow_headers": {
"accept": "*/*",
"connection": "close",
"content-length": "15",
"content-type": "application/json",
"host": "172.17.0.1",
"user-agent": "curl/7.43.0"
},
"__ow_path": ""
}
}
Enabling raw HTTP handling
Raw HTTP web actions are enabled via the --web flag using a value of
raw.
ops action create /guest/demo/hello hello.js --web raw
Disabling raw HTTP handling
Disabling raw HTTP can be accomplished by passing a value of false or
no to the --web flag.
ops update create /guest/demo/hello hello.js --web false
Decoding binary body content from Base64
When using raw HTTP handling, the __ow_body content will be encoded in
Base64 when the request content-type is binary. Below are functions
demonstrating how to decode the body content in Node, Python, and PHP.
Simply save a method shown below to file, create a raw HTTP web action
utilizing the saved artifact, and invoke the web action.
Node
function main(args) {
decoded = new Buffer(args.__ow_body, 'base64').toString('utf-8')
return {body: decoded}
}
Python
def main(args):
try:
decoded = args['__ow_body'].decode('base64').strip()
return {"body": decoded}
except:
return {"body": "Could not decode body from Base64."}
PHP
<?php
function main(array $args) : array
{
$decoded = base64_decode($args['__ow_body']);
return ["body" => $decoded];
}
As an example, save the Node function as decode.js and execute the
following commands:
$ ops action create decode decode.js --web raw
ok: created action decode
$ curl -k -H "content-type: application" -X POST -d "Decoded body" https://${APIHOST}/api/v1/web/guest/default/decodeNode.json
{
"body": "Decoded body"
}
Options Requests
By default, an OPTIONS request made to a web action will result in CORS
headers being automatically added to the response headers. These headers
allow all origins and the options, get, delete, post, put, head, and
patch HTTP verbs. In addition, the header
Access-Control-Request-Headers is echoed back as the header
Access-Control-Allow-Headers if it is present in the HTTP request.
Otherwise, a default value is generated as shown below.
Access-Control-Allow-Origin: *
Access-Control-Allow-Methods: OPTIONS, GET, DELETE, POST, PUT, HEAD, PATCH
Access-Control-Allow-Headers: Authorization, Origin, X-Requested-With, Content-Type, Accept, User-Agent
Alternatively, OPTIONS requests can be handled manually by a web action.
To enable this option add a web-custom-options annotation with a value
of true to a web action. When this feature is enabled, CORS headers
will not automatically be added to the request response. Instead, it is
the developer’s responsibility to append their desired headers
programmatically. Below is an example of creating custom responses to
OPTIONS requests.
function main(params) {
if (params.__ow_method == "options") {
return {
headers: {
'Access-Control-Allow-Methods': 'OPTIONS, GET',
'Access-Control-Allow-Origin': 'example.com'
},
statusCode: 200
}
}
}
Save the above function to custom-options.js and execute the following
commands:
$ ops action create custom-option custom-options.js --web true -a web-custom-options true
$ curl https://${APIHOST}/api/v1/web/guest/default/custom-options.http -kvX OPTIONS
< HTTP/1.1 200 OK
< Server: nginx/1.11.13
< Content-Length: 0
< Connection: keep-alive
< Access-Control-Allow-Methods: OPTIONS, GET
< Access-Control-Allow-Origin: example.com
Web Actions in Shared Packages
A web action in a shared (i.e., public) package is accessible as a web
action either directly via the package’s fully qualified name, or via a
package binding. It is important to note that a web action in a public
package will be accessible for all bindings of the package even if the
binding is private. This is because the web action annotation is carried
on the action and cannot be overridden. If you do not wish to expose a
web action through your package bindings, then you should clone-and-own
the package instead.
Action parameters are inherited from its package, and the binding if
there is one. You can make package parameters
immutable by defining their
values through a package binding.
Error Handling
When an OpenWhisk and OpenServerless action fails, there are two different
failure modes. The first is known as an application error and is
analogous to a caught exception: the action returns a JSON object
containing a top level error property. The second is a developer
error which occurs when the action fails catastrophically and does not
produce a response (this is similar to an uncaught exception). For web
actions, the controller handles application errors as follows:
The controller projects an error property from the response
object.
The controller applies the content handling implied by the action
extension to the value of the error property.
Developers should be aware of how web actions might be used and generate
error responses accordingly. For example, a web action that is used with
the .http extension should return an HTTP response, for example:
{error: { statusCode: 400 }. Failing to do so will in a mismatch
between the implied content-type from the extension and the action
content-type in the error response. Special consideration must be given
to web actions that are sequences, so that components that make up a
sequence can generate adequate errors when necessary.
3.1.3 - Parameters
Supply data to actions adding parameters
Introduction to parameters
When working with serverless actions, data is supplied by adding
parameters to the actions; these are in the parameter declared as an
argument to the main serverless function. All data arrives this way and
the values can be set in a few different ways. The first option is to
supply parameters when an action or package is created (or updated).
This approach is useful for data that stays the same on every execution,
equivalent to environment variables on other platforms, or for default
values that might be overridden at invocation time. The second option is
to supply parameters when the action is invoked - and this approach will
override any parameters already set.
This page outlines how to configure parameters when deploying packages
and actions, and how to supply parameters when invoking an action. There
is also information on how to use a file to store the parameters and
pass the filename, rather than supplying each parameter individually on
the command-line.
Passing parameters to an action at invoke time
Parameters can be passed to the action when it is invoked. These
examples use JavaScript but all the other languages work the same way.
- Use parameters in the action. For example, create ‘hello.js’ file
with the following content:
function main(params) {
return {payload: 'Hello, ' + params.name + ' from ' + params.place};
}
The input parameters are passed as a JSON object parameter to the main
function. Notice how the name and place parameters are retrieved
from the params object in this example.
- Update the action so it is ready to use:
ops action update hello hello.js
- Parameters can be provided explicitly on the command-line, or by
supplying a file containing the desired parameters
To pass parameters directly through the command-line, supply a key/value
pair to the --param flag:
ops action invoke --result hello --param name Dorothy --param place Kansas
This produces the result:
{
"payload": "Hello, Dorothy from Kansas"
}
Notice the use of the --result option: it implies a blocking
invocation where the CLI waits for the activation to complete and then
displays only the result. For convenience, this option may be used
without --blocking which is automatically inferred.
Additionally, if parameter values specified on the command-line are
valid JSON, then they will be parsed and sent to your action as a
structured object. For example, if we update our hello action to:
function main(params) {
return {payload: 'Hello, ' + params.person.name + ' from ' + params.person.place};
}
Now the action expects a single person parameter to have fields name
and place. If we invoke the action with a single person parameter
that is valid JSON:
ops action invoke --result hello -p person '{"name": "Dorothy", "place": "Kansas"}'
The result is the same because the CLI automatically parses the person
parameter value into the structured object that the action now expects:
json { "payload": "Hello, Dorothy from Kansas" }
Setting default parameters on an action
Actions can be invoked with multiple named parameters. Recall that the
hello action from the previous example expects two parameters: the
name of a person, and the place where they’re from.
Rather than pass all the parameters to an action every time, you can
bind certain parameters. The following example binds the place
parameter so that the action defaults to the place “Kansas”:
- Update the action by using the
--param option to bind parameter
values, or by passing a file that contains the parameters to
--param-file (for examples of using files, see the section on
working with parameter files.
To specify default parameters explicitly on the command-line, provide a
key/value pair to the param flag:
ops action update hello --param place Kansas
- Invoke the action, passing only the
name parameter this time.
ops action invoke --result hello --param name Dorothy
{
"payload": "Hello, Dorothy from Kansas"
}
Notice that you did not need to specify the place parameter when you
invoked the action. Bound parameters can still be overwritten by
specifying the parameter value at invocation time.
- Invoke the action, passing both
name and place values, and
observe the output:
ops action invoke --result hello --param name Dorothy --param place "Washington, DC"
{
"payload": "Hello, Dorothy from Washington, DC"
}
Despite a parameter set on the action when it was created/updated, this
is overridden by a parameter that was supplied when invoking the action.
Setting default parameters on a package
Parameters can be set at the package level, and these will serve as
default parameters for actions unless:
The action itself has a default parameter.
The action has a parameter supplied at invoke time, which will
always be the “winner” where more than one parameter is available.
The following example sets a default parameter of name on the MyApp
package and shows an action making use of it.
- Create a package with a parameter set:
ops package update MyApp --param name World
- Create an action in this package:
function main(params) {
return {payload: "Hello, " + params.name};
}
ops action update MyApp/hello hello.js
- Invoke the action, and observe the default package parameter in use:
ops action invoke --result MyApp/hello
{
"payload": "Hello, World"
}
Working with parameter files
It’s also possible to put parameters into a file in JSON format, and
then pass the parameters in by supplying the filename with the
param-file flag. This works for both packages and actions when
creating/updating them, and when invoking actions.
- As an example, consider the very simple
hello example from
earlier. Using hello.js with this content:
function main(params) {
return {payload: 'Hello, ' + params.name + ' from ' + params.place};
}
- Update the action with the updated contents of
hello.js:
ops action update hello hello.js
- Create a parameter file called
parameters.json containing
JSON-formatted parameters:
{
"name": "Dorothy",
"place": "Kansas"
}
- Use the
parameters.json filename when invoking the action, and
observe the output
ops action invoke --result hello --param-file parameters.json
{
"payload": "Hello, Dorothy from Kansas"
}
3.1.4 - Annotations
How to use annotations to decorate actions
Annotations
OpenWhisk and OpenServerless actions, triggers, rules and packages
(collectively referred to as assets) may be decorated with
annotations. Annotations are attached to assets just like parameters
with a key that defines a name and value that defines the value. It
is convenient to set them from the command line interface (CLI) via
--annotation or -a for short.
Rationale: Annotations were added to OpenWhisk and OpenServerless to allow
for experimentation without making changes to the underlying asset
schema. We had, until the writing of this document, deliberately not
defined what annotations are permitted. However as we start to use
annotations more heavily to impart semantic changes, it’s important that
we finally start to document them.
The most prevalent use of annotations to date is to document actions and
packages. You’ll see many of the packages in the OpenWhisk and OpenServerless
catalog carry annotations such as a description of the functionality
offered by their actions, which parameters are required at package
binding time, and which are invoke-time parameters, whether a parameter
is a “secret” (e.g., password), or not. We have invented these as
needed, for example to allow for UI integration.
Here is a sample set of annotations for an echo action which returns
its input arguments unmodified (e.g.,
function main(args) { return args }). This action may be useful for
logging input parameters for example as part of a sequence or rule.
ops action create echo echo.js \
-a description 'An action which returns its input. Useful for logging input to enable debug/replay.' \
-a parameters '[{ "required":false, "description": "Any JSON entity" }]' \
-a sampleInput '{ "msg": "Five fuzzy felines"}' \
-a sampleOutput '{ "msg": "Five fuzzy felines"}'
The annotations we have used for describing packages are:
Similarly, for actions:
description: a pithy description of the action
parameters: an array describing actions that are required to
execute the action
sampleInput: an example showing the input schema with typical
values
sampleOutput: an example showing the output schema, usually for
the sampleInput
The annotations we have used for describing parameters include:
name: the name of the parameter
description: a pithy description of the parameter
doclink: a link to further documentation for parameter (useful for
OAuth tokens for example)
required: true for required parameters and false for optional ones
bindTime: true if the parameter should be specified when a package
is bound
type: the type of the parameter, one of password, array (but
may be used more broadly)
The annotations are not checked. So while it is conceivable to use the
annotations to infer if a composition of two actions into a sequence is
legal, for example, the system does not yet do that.
Annotations for all actions
The following annotations on an action are available.
provide-api-key: This annotation may be attached to actions which
require an API key, for example to make REST API calls to the
OpenWhisk and OpenServerless host. For newly created actions, if not
specified, it defaults to a false value. For existing actions, the
absence of this annotation, or its presence with a value that is not
falsy (i.e., a value that is different from zero, null, false, and
the empty string) will cause an API key to be present in the action
execution context.
Annotations specific to web actions
Web actions are enabled with explicit annotations which decorate
individual actions. The annotations only apply to the web
actions API, and must be present and explicitly set
to true to have an affect. The annotations have no meaning otherwise
in the system. The annotations are:
web-export: Makes its corresponding action accessible to REST
calls without authentication. We call these web
actions because they allow one to use OpenWhisk
and OpenServerless actions from a browser for example. It is important to
note that the owner of the web action incurs the cost of running
them in the system (i.e., the owner of the action also owns the
activations record). The rest of the annotations described below
have no effect on the action unless this annotation is also set.
final: Makes all of the action parameters that are already defined
immutable. A parameter of an action carrying the annotation may not
be overridden by invoke-time parameters once the parameter has a
value defined through its enclosing package or the action
definition.
raw-http: When set, the HTTP request query and body parameters are
passed to the action as reserved properties.
web-custom-options: When set, this annotation enables a web action
to respond to OPTIONS requests with customized headers, otherwise a
default CORS response applies.
require-whisk-auth: This annotation protects the web action so
that it is only invoked by requests that provide appropriate
authentication credentials. When set to a boolean value, it controls
whether or not the request’s Basic Authentication value (i.e. Whisk
auth key) will be authenticated - a value of true will
authenticate the credentials, a value of false will invoke the
action without any authentication. When set to a number or a string,
this value must match the request’s X-Require-Whisk-Auth header
value. In both cases, it is important to note that the owner of
the web action will still incur the cost of running them in the
system (i.e., the owner of the action also owns the activations
record).
Annotations specific to activations
The system decorates activation records with annotations as well. They
are:
path: the fully qualified path name of the action that generated
the activation. Note that if this activation was the result of an
action in a package binding, the path refers to the parent package.
binding: the entity path of the package binding. Note that this is
only present for actions in a package binding.
kind: the kind of action executed, and one of the support
OpenWhisk and OpenServerless runtime kinds.
limits: the time, memory and log limits that this activation were
subject to.
Additionally for sequence related activations, the system will generate
the following annotations:
Lastly, and in order to provide you with some performance transparency,
activations also record:
waitTime: the time spent waiting in the internal OpenWhisk and
OpenServerless system. This is roughly the time spent between the
controller receiving the activation request and when the invoker
provisioned a container for the action.
initTime: the time spent initializing the function. If this value
is present, the action required initialization and represents a cold
start. A warm activation will skip initialization, and in this case,
the annotation is not generated.
An example of these annotations as they would appear in an activation
record is shown below.
"annotations": [
{
"key": "path",
"value": "guest/echo"
},
{
"key": "waitTime",
"value": 66
},
{
"key": "kind",
"value": "nodejs:6"
},
{
"key": "initTime",
"value": 50
},
{
"key": "limits",
"value": {
"logs": 10,
"memory": 256,
"timeout": 60000
}
}
]
3.1.5 - Packages
Create and Use packages
In OpenWhisk and OpenServerless, you can use packages to bundle together a
set of related actions, and share them with others.
A package can include actions and feeds. - An action is a piece of
code that runs on OpenWhisk. For example, the Cloudant
package includes actions to read and write records to a Cloudant
database. - A feed is used to configure an external event source to fire
trigger events. For example, the Alarm package includes a feed that can
fire a trigger at a specified frequency.
Every OpenWhisk and OpenServerless entity, including packages, belongs in a
namespace, and the fully qualified name of an entity is
/namespaceName[/packageName]/entityName. Refer to the naming
guidelines for more information.
The following sections describe how to browse packages and use the
triggers and feeds in them. In addition, if you are interested in
contributing your own packages to the catalog, read the sections on
creating and sharing packages.
Browsing packages
Several packages are registered with OpenWhisk and OpenServerless. You can
get a list of packages in a namespace, list the entities in a package,
and get a description of the individual entities in a package.
- Get a list of packages in the
/nuvolaris namespace.
$ ops package list /nuvolaris
packages
/nuvolaris/openai private
/nuvolaris/mastrogpt private
/nuvolaris/examples private
- Get a list of entities in the
/nuvolaris/openai package.
$ ops package get --summary /nuvolaris/openai
package /nuvolaris/openai
(parameters: none defined)
action /nuvolaris/openai/models
(parameters: none defined)
action /nuvolaris/openai/chat
(parameters: none defined)
Note: Parameters listed under the package with a prefix * are
predefined, bound parameters. Parameters without a * are those listed
under the annotations for each entity. Furthermore,
any parameters with the prefix ** are finalized bound parameters. This
means that they are immutable, and cannot be changed by the user. Any
entity listed under a package inherits specific bound parameters from
the package. To view the list of known parameters of an entity belonging
to a package, you will need to run a get --summary of the individual
entity.
- Get a description of the
/nuvolaris/openai/chat action.
$ ops action get --summary /nuvolaris/openai/chat
action /nuvolaris/openai/chat: Returns a result based on parameters OPENAI_API_HOST and OPENAI_API_KEY
(parameters: **OPENAI_API_HOST, **OPENAI_API_KEY)
NOTE: Notice that the parameters listed for the action read were
expanded upon from the action summary compared to the package summary
above. To see the official bound parameters for actions and triggers
listed under packages, run an individual get summary for the particular
entity.
Creating a package
A package is used to organize a set of related actions and feeds. It
also allows for parameters to be shared across all entities in the
package.
To create a custom package with a simple action in it, try the following
example:
- Create a package called
custom.
$ ops package create custom
ok: created package custom
- Get a summary of the package.
$ ops package get --summary custom
package /myNamespace/custom
(parameters: none defined)
Notice that the package is empty.
- Create a file called
identity.js that contains the following
action code. This action returns all input parameters.
function main(args) { return args; }
- Create an
identity action in the custom package.
$ ops action create custom/identity identity.js
ok: created action custom/identity
Creating an action in a package requires that you prefix the action name
with a package name. Package nesting is not allowed. A package can
contain only actions and can’t contain another package.
- Get a summary of the package again.
$ ops package get --summary custom
package /myNamespace/custom
(parameters: none defined)
action /myNamespace/custom/identity
(parameters: none defined)
You can see the custom/identity action in your namespace now.
- Invoke the action in the package.
$ ops action invoke --result custom/identity
{}
You can set default parameters for all the entities in a package. You do
this by setting package-level parameters that are inherited by all
actions in the package. To see how this works, try the following
example:
- Update the
custom package with two parameters: city and
country.
$ ops package update custom --param city Austin --param country USA
ok: updated package custom
- Display the parameters in the package and action, and see how the
identity action in the package inherits parameters from the
package.
$ ops package get custom
ok: got package custom
...
"parameters": [
{
"key": "city",
"value": "Austin"
},
{
"key": "country",
"value": "USA"
}
]
...
$ ops action get custom/identity
ok: got action custom/identity
...
"parameters": [
{
"key": "city",
"value": "Austin"
},
{
"key": "country",
"value": "USA"
}
]
...
- Invoke the identity action without any parameters to verify that the
action indeed inherits the parameters.
$ ops action invoke --result custom/identity
{
"city": "Austin",
"country": "USA"
}
- Invoke the identity action with some parameters. Invocation
parameters are merged with the package parameters; the invocation
parameters override the package parameters.
$ ops action invoke --result custom/identity --param city Dallas --param state Texas
{
"city": "Dallas",
"country": "USA",
"state": "Texas"
}
Sharing a package
After the actions and feeds that comprise a package are debugged and
tested, the package can be shared with all OpenWhisk and OpenServerless
users. Sharing the package makes it possible for the users to bind the
package, invoke actions in the package, and author OpenWhisk and
OpenServerless rules and sequence actions.
- Share the package with all users:
$ ops package update custom --shared yes
ok: updated package custom
- Display the
publish property of the package to verify that it is
now true.
$ ops package get custom
ok: got package custom
...
"publish": true,
...
Others can now use your custom package, including binding to the
package or directly invoking an action in it. Other users must know the
fully qualified names of the package to bind it or invoke actions in it.
Actions and feeds within a shared package are public. If the package
is private, then all of its contents are also private.
- Get a description of the package to show the fully qualified names
of the package and action.
$ ops package get --summary custom
package /myNamespace/custom: Returns a result based on parameters city and country
(parameters: *city, *country)
action /myNamespace/custom/identity
(parameters: none defined)
In the previous example, you’re working with the myNamespace
namespace, and this namespace appears in the fully qualified name.
3.1.6 - Feeds
Implement Feeds
OpenWhisk and OpenServerless support an open API, where any user can expose
an event producer service as a feed in a package. This section
describes architectural and implementation options for providing your
own feed.
This material is intended for advanced OpenWhisk and OpenServerless users who
intend to publish their own feeds. Most OpenWhisk and OpenServerless users
can safely skip this section.
Feed Architecture
There are at least 3 architectural patterns for creating a feed:
Hooks, Polling and Connections.
Hooks
In the Hooks pattern, we set up a feed using a
webhook facility exposed by
another service. In this strategy, we configure a webhook on an external
service to POST directly to a URL to fire a trigger. This is by far the
easiest and most attractive option for implementing low-frequency feeds.
Polling
In the Polling pattern, we arrange for an OpenWhisk and OpenServerless
action to poll an endpoint periodically to fetch new data. This
pattern is relatively easy to build, but the frequency of events will of
course be limited by the polling interval.
Connections
In the Connections pattern, we stand up a separate service somewhere
that maintains a persistent connection to a feed source. The connection
based implementation might interact with a service endpoint via long
polling, or to set up a push notification.
Difference between Feed and Trigger
Feeds and triggers are closely related, but technically distinct
concepts.
OpenWhisk and OpenServerless process events which flow into the
system.
A trigger is technically a name for a class of events. Each
event belongs to exactly one trigger; by analogy, a trigger
resembles a topic in topic-based pub-sub systems. A rule T →
A means “whenever an event from trigger T arrives, invoke action
A with the trigger payload.
A feed is a stream of events which all belong to some trigger
T. A feed is controlled by a feed action which handles
creating, deleting, pausing, and resuming the stream of events which
comprise a feed. The feed action typically interacts with external
services which produce the events, via a REST API that manages
notifications.
Implementing Feed Actions
The feed action is a normal OpenWhisk and OpenServerless action, but it
should accept the following parameters:
- lifecycleEvent: one of ‘CREATE’, ‘READ’, ‘UPDATE’, ‘DELETE’, ‘PAUSE’, or ‘UNPAUSE’.
- triggerName: the fully-qualified name of the trigger which contains
events produced from this feed.
- authKey: the Basic auth
credentials of the OpenWhisk and OpenServerless user who owns the trigger
just mentioned.
The feed action can also accept any other parameters it needs to manage
the feed. For example the cloudant changes feed action expects to
receive parameters including `dbname’, `username’, etc.
When the user creates a trigger from the CLI with the –feed
parameter, the system automatically invokes the feed action with the
appropriate parameters.
For example, assume the user has created a mycloudant binding for the
cloudant package with their username and password as bound parameters.
When the user issues the following command from the CLI:
ops trigger create T --feed mycloudant/changes -p dbName myTable
then under the covers the system will do something equivalent to:
ops action invoke mycloudant/changes -p lifecycleEvent CREATE -p triggerName T -p authKey <userAuthKey> -p password <password value from mycloudant binding> -p username <username value from mycloudant binding> -p dbName mytype
The feed action named changes takes these parameters, and is expected
to take whatever action is necessary to set up a stream of events from
Cloudant, with the appropriate configuration, directed to the trigger
T.
For the Cloudant changes feed, the action happens to talk directly to
a cloudant trigger service we’ve implemented with a connection-based
architecture. We’ll discuss the other architectures below.
A similar feed action protocol occurs for ops trigger delete,
ops trigger update and ops trigger get.
Implementing Feeds with Hooks
It is easy to set up a feed via a hook if the event producer supports a
webhook/callback facility.
With this method there is no need to stand up any persistent service
outside of OpenWhisk and OpenServerless. All feed management happens
naturally though stateless OpenWhisk and OpenServerless feed actions, which
negotiate directly with a third part webhook API.
When invoked with CREATE, the feed action simply installs a webhook
for some other service, asking the remote service to POST notifications
to the appropriate fireTrigger URL in OpenWhisk and OpenServerless.
The webhook should be directed to send notifications to a URL such as:
POST /namespaces/{namespace}/triggers/{triggerName}
The form with the POST request will be interpreted as a JSON document
defining parameters on the trigger event. OpenWhisk and OpenServerless rules
pass these trigger parameters to any actions to fire as a result of the
event.
Implementing Feeds with Polling
It is possible to set up an OpenWhisk and OpenServerless action to poll a
feed source entirely within OpenWhisk and OpenServerless, without the need to
stand up any persistent connections or external service.
For feeds where a webhook is not available, but do not need high-volume
or low latency response times, polling is an attractive option.
To set up a polling-based feed, the feed action takes the following
steps when called for CREATE:
The feed action sets up a periodic trigger (T) with the desired
frequency, using the whisk.system/alarms feed.
The feed developer creates a pollMyService action which simply
polls the remote service and returns any new events.
The feed action sets up a rule T → pollMyService.
This procedure implements a polling-based trigger entirely using
OpenWhisk and OpenServerless actions, without any need for a separate
service.
Implementing Feeds via Connections
The previous 2 architectural choices are simple and easy to implement.
However, if you want a high-performance feed, there is no substitute for
persistent connections and long-polling or similar techniques.
Since OpenWhisk and OpenServerless actions must be short-running, an action
cannot maintain a persistent connection to a third party . Instead, we
must stand up a separate service (outside of OpenWhisk and OpenServerless)
that runs all the time. We call these provider services. A provider
service can maintain connections to third party event sources that
support long polling or other connection-based notifications.
The provider service should provide a REST API that allows the OpenWhisk
and OpenServerless feed action to control the feed. The provider service
acts as a proxy between the event provider and OpenWhisk and OpenServerless –
when it receives events from the third party, it sends them on to
OpenWhisk and OpenServerless by firing a trigger.
The connection-based architecture is the highest performance option, but
imposes more overhead on operations compared to the polling and hook
architectures.
3.2 - Advanced Reference Guide
Advanced documentation
In this section, you can find advanced reference documentations here.
Please follow the links below.
3.2.1 - Advanced CLI
How to use the advanced features of ops command line
OpenServerless Cli
OpenServerless offers a powerful command line interface named ops which
extends and embeds the OpenWhisk wsk.
Download instructions are available here.
Let’s see some advanced uses of ops.
OpenServerless access is usually configured logging into the platform with the ops -login command.
You can also configure access directly using the ops -wsk command.
There are two required properties to configure:
API host (name or IP address) for the OpenWhisk and OpenServerless
deployment you want to use.
Authorization key (username and password) which grants you
access to the OpenWhisk and OpenServerless API.
The API host is the installation host, the one you configure in
installation with ops config apihost
ops -wsk property set --apihost <openwhisk_baseurl>
If you know your authorization key, you can configure the CLI to use it.
Otherwise, you will need to obtain an authorization key for most CLI
operations. The API key is visible in the file ~/.wskprops after you
perform a ops -login. This file can be sourced to be read as
environment variables.
source ~/.wskprops
ops -wsk property set --auth $AUTH
Tip: The OpenWhisk and OpenServerless CLI stores properties in the
~/.wskprops configuration file by default. The location of this file
can be altered by setting the WSK_CONFIG_FILE environment variable.
The required properties described above have the following keys in the
.wskprops file:
To verify your CLI setup, try ops action list.
The CLI can be setup to use an HTTPS proxy. To setup an HTTPS proxy, an
environment variable called HTTPS_PROXY must be created. The variable
must be set to the address of the HTTPS proxy, and its port using the
following format: {PROXY IP}:{PROXY PORT}.
The CLI has an extra level of security from client to apihost, system
provides default client certificate configuration which deployment
process generated, then you can refer to below steps to use client
certificate:
ops -wsk property set --cert <client_cert_path> --key <client_key_path>
3.2.2 - Naming Limits
Details of OpenServerless and OpenWhisk system
The following sections provide more details about the OpenWhisk and
OpenServerless system.
Entities
Namespaces and packages
OpenWhisk and OpenServerless actions, triggers, and rules belong in a
namespace, and optionally a package.
Packages can contain actions and feeds. A package cannot contain another
package, so package nesting is not allowed. Also, entities do not have
to be contained in a package.
In OpenServerless a namespace corresponds to an user. You can create users
with the admin subcommand of the CLI.
The fully qualified name of an entity is
/namespaceName[/packageName]/entityName. Notice that / is used to
delimit namespaces, packages, and entities.
If the fully qualified name has three parts:
/namespaceName/packageName/entityName, then the namespace can be
entered without a prefixed /; otherwise, namespaces must be prefixed
with a /.
For convenience, the namespace can be left off if it is the user’s
default namespace.
For example, consider a user whose default namespace is /myOrg.
Following are examples of the fully qualified names of a number of
entities and their aliases.
/whisk.system/cloudant/read
| | /whisk.system
| cloudant
| read
|
/myOrg/video/transcode
| video/transcode
| /myOrg
| video
| transcode
|
/myOrg/filter
| filter
| /myOrg
| | filter
|
You will be using this naming scheme when you use the OpenWhisk and
OpenServerless CLI, among other places.
Entity names
The names of all entities, including actions, triggers, rules, packages,
and namespaces, are a sequence of characters that follow the following
format:
The first character must be an alphanumeric character, or an
underscore.
The subsequent characters can be alphanumeric, spaces, or any of the
following: _, @, ., -.
The last character can’t be a space.
More precisely, a name must match the following regular expression
(expressed with Java metacharacter syntax):
\A([\w]|[\w][\w@ .-]*[\w@.-]+)\z.
System limits
Actions
OpenWhisk and OpenServerless has a few system limits, including how much
memory an action can use and how many action invocations are allowed per
minute.
Note: On Openwhisk 2.0 with the scheduler service, concurrent in
the table below really means the max containers that can be provisioned
at once for a namespace. The api may be able to accept more
activations than this number at once depending on a number of factors.
The following table lists the default limits for actions.
timeout | a container is not allowed to run
longer than N milliseconds | per action | milliseconds | 60000 |
memory | a container is not allowed to allocate
more than N MB of memory | per action | MB | 256 |
logs | a container is not allowed to write
more than N MB to stdout | per action | MB | 10 |
instances | an action is not allowed to have more
containers than this value (new scheduler
only) | per action | number | namespace concurrency limit |
concurrent | no more than N activations may be
submitted per namespace either executing or queued for
execution | per namespace | number | 100 |
minuteRate | no more than N activations may be
submitted per namespace per minute | per namespace | number | 120 |
codeSize | the maximum size of the action
code | configurable, limit per action | MB | 48 |
parameters | the maximum size of the parameters that
can be attached | not configurable, limit per
action/package/trigger | MB | 1 |
result | the maximum size of the action
result | not configurable, limit per
action | MB | 1 |
Per action timeout (ms) (Default: 60s)
The timeout limit N is in the range [100ms..300000ms] and is set
per action in milliseconds.
A user can change the limit when creating the action.
A container that runs longer than N milliseconds is terminated.
Per action memory (MB) (Default: 256MB)
The memory limit M is in the range from [128MB..512MB] and is set
per action in MB.
A user can change the limit when creating the action.
A container cannot have more memory allocated than the limit.
Per action max instance concurrency (Default: namespace limit for concurrent invocations) Only applicable using new scheduler
The max containers that will be created for an action before
throttling in the range from [1..concurrentInvocations limit for
namespace]
By default the max allowed containers / server instances for an
action is equal to the namespace limit.
A user can change the limit when creating the action.
Defining a lower limit than the namespace limit means your max
container concurrency will be the action defined limit.
If using actionConcurrency > 1 such that your action can handle
multiple requests per instance, your true concurrency limit is
actionContainerConcurrency * actionConcurrency.
The actions within a namespaces containerConcurrency total do not
have to add up to the namespace limit though you can configure it
that way to guarantee an action will get exactly the action
container concurrency.
For example with a namespace limit of 30 with 2 actions each with a
container limit of 20; if the first action is using 20, there will
still be space for 10 for the other.
Per action logs (MB) (Default: 10MB)
The log limit N is in the range [0MB..10MB] and is set per action.
A user can change the limit when creating or updating the action.
Logs that exceed the set limit are truncated and a warning is added
as the last output of the activation to indicate that the activation
exceeded the set log limit.
Per action artifact (MB) (Default: 48MB)
Per activation payload size (MB) (Fixed: 1MB)
- The maximum POST content size plus any curried parameters for an
action invocation or trigger firing is 1MB.
Per activation result size (MB) (Fixed: 1MB)
- The maximum size of a result returned from an action is 1MB.
Per namespace concurrent invocation (Default: 100)
Invocations per minute (Fixed: 120)
The rate limit N is set to 120 and limits the number of action
invocations in one minute windows.
A user cannot change this limit when creating the action.
A CLI or API call that exceeds this limit receives an error code
corresponding to HTTP status code 429: TOO MANY REQUESTS.
Size of the parameters (Fixed: 1MB)
The size limit for the parameters on creating or updating of an
action/package/trigger is 1MB.
The limit cannot be changed by the user.
An entity with too big parameters will be rejected on trying to
create or update it.
Per Docker action open files ulimit (Fixed: 1024:1024)
The maximum number of open files is 1024 (for both hard and soft
limits).
The docker run command use the argument --ulimit nofile=1024:1024.
For more information about the ulimit for open files see the docker
run
documentation.
Per Docker action processes ulimit (Fixed: 1024)
The maximum number of processes available to the action container is
1024.
The docker run command use the argument --pids-limit 1024.
For more information about the ulimit for maximum number of
processes see the docker
run
documentation.
Triggers
Triggers are subject to a firing rate per minute as documented in the
table below.
minuteRate | no more than N triggers may be fired
per namespace per minute | per user | number | 60 |
Triggers per minute (Fixed: 60)
The rate limit N is set to 60 and limits the number of triggers that
may be fired in one minute windows.
A user cannot change this limit when creating the trigger.
A CLI or API call that exceeds this limit receives an error code
corresponding to HTTP status code 429: TOO MANY REQUESTS.
3.2.3 - Rest API
Use OpenServerless with your Rest API calls.
Using REST APIs with OpenWhisk and OpenServerless
After your OpenWhisk and OpenServerlesss environment is enabled, you can use
it with your web apps or mobile apps with REST API calls.
For more details about the APIs for actions, activations, packages,
rules, and triggers, see the OpenWhisk and OpenServerless API
documentation.
All the capabilities in the system are available through a REST API.
There are collection and entity endpoints for actions, triggers, rules,
packages, activations, and namespaces.
These are the collection endpoints:
https://$APIHOST/api/v1/namespaces
https://$APIHOST/api/v1/namespaces/{namespace}/actions
https://$APIHOST/api/v1/namespaces/{namespace}/triggers
https://$APIHOST/api/v1/namespaces/{namespace}/rules
https://$APIHOST/api/v1/namespaces/{namespace}/packages
https://$APIHOST/api/v1/namespaces/{namespace}/activations
https://$APIHOST/api/v1/namespaces/{namespace}/limits
The $APIHOST is the OpenWhisk and OpenServerless API hostname (for example,
localhost, 172.17.0.1, and so on). For the {namespace}, the character
_ can be used to specify the user’s default namespace.
You can perform a GET request on the collection endpoints to fetch a
list of entities in the collection.
There are entity endpoints for each type of entity:
https://$APIHOST/api/v1/namespaces/{namespace}
https://$APIHOST/api/v1/namespaces/{namespace}/actions/[{packageName}/]{actionName}
https://$APIHOST/api/v1/namespaces/{namespace}/triggers/{triggerName}
https://$APIHOST/api/v1/namespaces/{namespace}/rules/{ruleName}
https://$APIHOST/api/v1/namespaces/{namespace}/packages/{packageName}
https://$APIHOST/api/v1/namespaces/{namespace}/activations/{activationName}
The namespace and activation endpoints support only GET requests. The
actions, triggers, rules, and packages endpoints support GET, PUT, and
DELETE requests. The endpoints of actions, triggers, and rules also
support POST requests, which are used to invoke actions and triggers and
enable or disable rules.
All APIs are protected with HTTP Basic authentication. You can use the
ops admin tool to generate a new namespace and
authentication. The Basic authentication credentials are in the AUTH
property in your ~/.nuvprops file, delimited by a colon. You can also
retrieve these credentials using the CLI running
ops property get --auth.
The following is an example that uses the cURL
command tool to get the list of all packages in the whisk.system
namespace:
curl -u USERNAME:PASSWORD https://$APIHOST/api/v1/namespaces/whisk.system/packages
[
{
"name": "slack",
"binding": false,
"publish": true,
"annotations": [
{
"key": "description",
"value": "Package that contains actions to interact with the Slack messaging service"
}
],
"version": "0.0.1",
"namespace": "whisk.system"
}
]
In this example the authentication was passed using the -u flag, you
can pass this value also as part of the URL as
https://USERNAME:PASSWORD@$APIHOST.
The OpenWhisk API supports request-response calls from web clients.
OpenWhisk responds to OPTIONS requests with Cross-Origin Resource
Sharing headers. Currently, all origins are allowed (that is,
Access-Control-Allow-Origin is “*”), the standard set of methods are
allowed (that is, Access-Control-Allow-Methods is
GET, DELETE, POST, PUT, HEAD), and Access-Control-Allow-Headers yields
Authorization, Origin, X-Requested-With, Content-Type, Accept, User-Agent.
Attention: Because OpenWhisk and OpenServerless currently supports only
one key per namespace, it is not recommended to use CORS beyond simple
experiments. Use Web Actions to expose your actions
to the public and not use the OpenWhisk and OpenServerless authorization key
for client applications that require CORS.
Using the CLI verbose mode
The OpenWhisk and OpenServerless CLI is an interface to the OpenWhisk and
OpenServerless REST API. You can run the CLI in verbose mode with the flag
-v, this will print truncated information about the HTTP request and
response. To print all information use the flag -d for debug.
Note: HTTP request and response bodies will only be truncated if
they exceed 1000 bytes.
Let’s try getting the namespace value for the current user.
ops namespace list -v
REQUEST:
[GET] https://$APIHOST/api/v1/namespaces
Req Headers
{
"Authorization": [
"Basic XXXYYYY"
],
"User-Agent": [
"OpenWhisk and OpenServerless-CLI/1.0 (2017-08-10T20:09:30+00:00)"
]
}
RESPONSE:Got response with code 200
Resp Headers
{
"Content-Type": [
"application/json; charset=UTF-8"
]
}
Response body size is 28 bytes
Response body received:
["john@example.com_dev"]
As you can see you the printed information provides the properties of
the HTTP request, it performs a HTTP method GET on the URL
https://$APIHOST/api/v1/namespaces using a User-Agent header
OpenWhisk and OpenServerless-CLI/1.0 (<CLI-Build-version>) and Basic
Authorization header Basic XXXYYYY. Notice that the authorization
value is your base64-encoded OpenWhisk and OpenServerless authorization
string. The response is of content type application/json.
Actions
Note: In the examples that follow, $AUTH and $APIHOST represent
environment variables set respectively to your OpenWhisk and OpenServerless
authorization key and API host.
To create or update an action send a HTTP request with method PUT on
the the actions collection. For example, to create a nodejs:6 action
with the name hello using a single file content use the following:
curl -u $AUTH -d '{"namespace":"_","name":"hello","exec":{"kind":"nodejs:6","code":"function main(params) { return {payload:\"Hello \"+params.name}}"}}' -X PUT -H "Content-Type: application/json" https://$APIHOST/api/v1/namespaces/_/actions/hello?overwrite=true
To perform a blocking invocation on an action, send a HTTP request with
a method POST and body containing the input parameter name use the
following:
curl -u $AUTH https://$APIHOST/api/v1/namespaces/_/actions/hello?blocking=true \
-X POST -H "Content-Type: application/json" \
-d '{"name":"John"}'
You get the following response:
{
"duration": 2,
"name": "hello",
"subject": "john@example.com_dev",
"activationId": "c7bb1339cb4f40e3a6ccead6c99f804e",
"publish": false,
"annotations": [{
"key": "limits",
"value": {
"timeout": 60000,
"memory": 256,
"logs": 10
}
}, {
"key": "path",
"value": "john@example.com_dev/hello"
}],
"version": "0.0.1",
"response": {
"result": {
"payload": "Hello John"
},
"success": true,
"status": "success"
},
"end": 1493327653769,
"logs": [],
"start": 1493327653767,
"namespace": "john@example.com_dev"
}
If you just want to get the response.result, run the command again
with the query parameter result=true
curl -u $AUTH "https://$APIHOST/api/v1/namespaces/_/actions/hello?blocking=true&result=true" \
-X POST -H "Content-Type: application/json" \
-d '{"name":"John"}'
You get the following response:
{
"payload": "hello John"
}
Annotations and Web Actions
To create an action as a web action, you need to add an
annotation of web-export=true for web actions.
Since web-actions are publicly accessible, you should protect
pre-defined parameters (i.e., treat them as final) using the annotation
final=true. If you create or update an action using the CLI flag
--web true this command will add both annotations web-export=true
and final=true.
Run the curl command providing the complete list of annotations to set
on the action
curl -u $AUTH https://$APIHOST/api/v1/namespaces/_/actions/hello?overwrite=true \
-X PUT -H "Content-Type: application/json" \
-d '{"namespace":"_","name":"hello","exec":{"kind":"nodejs:6","code":"function main(params) { return {payload:\"Hello \"+params.name}}"},"annotations":[{"key":"web-export","value":true},{"key":"raw-http","value":false},{"key":"final","value":true}]}'
You can now invoke this action as a public URL with no OpenWhisk and
OpenServerless authorization. Try invoking using the web action public URL
including an optional extension such as .json or .http for example
at the end of the URL.
curl https://$APIHOST/api/v1/web/john@example.com_dev/default/hello.json?name=John
{
"payload": "Hello John"
}
Note that this example source code will not work with .http, see web
actions documentation on how to modify.
Sequences
To create an action sequence, you need to create it by providing the
names of the actions that compose the sequence in the desired order, so
the output from the first action is passed as input to the next action.
$ ops action create sequenceAction –sequence
/whisk-system/utils/split,/whisk-system/utils/sort
Create a sequence with the actions /whisk-system/utils/split and
/whisk-system/utils/sort.
curl -u $AUTH https://$APIHOST/api/v1/namespaces/_/actions/sequenceAction?overwrite=true \
-X PUT -H "Content-Type: application/json" \
-d '{"namespace":"_","name":"sequenceAction","exec":{"kind":"sequence","components":["/whisk.system/utils/split","/whisk.system/utils/sort"]},"annotations":[{"key":"web-export","value":true},{"key":"raw-http","value":false},{"key":"final","value":true}]}'
Take into account when specifying the names of the actions, they have to
be full qualified.
Triggers
To create a trigger, the minimum information you need is a name for the
trigger. You could also include default parameters that get passed to
the action through a rule when the trigger gets fired.
Create a trigger with name events with a default parameter type with
value webhook set.
curl -u $AUTH https://$APIHOST/api/v1/namespaces/_/triggers/events?overwrite=true \
-X PUT -H "Content-Type: application/json" \
-d '{"name":"events","parameters":[{"key":"type","value":"webhook"}]}'
Now whenever you have an event that needs to fire this trigger it just
takes an HTTP request with a method POST using the OpenWhisk and
OpenServerless Authorization key.
To fire the trigger events with a parameter temperature, send the
following HTTP request.
curl -u $AUTH https://$APIHOST/api/v1/namespaces/_/triggers/events \
-X POST -H "Content-Type: application/json" \
-d '{"temperature":60}'
Rules
To create a rule that associates a trigger with an action, send a HTTP
request with a PUT method providing the trigger and action in the body
of the request.
curl -u $AUTH https://$APIHOST/api/v1/namespaces/_/rules/t2a?overwrite=true \
-X PUT -H "Content-Type: application/json" \
-d '{"name":"t2a","status":"","trigger":"/_/events","action":"/_/hello"}'
Rules can be enabled or disabled, and you can change the status of the
rule by updating its status property. For example, to disable the rule
t2a send in the body of the request status: "inactive" with a POST
method.
curl -u $AUTH https://$APIHOST/api/v1/namespaces/_/rules/t2a?overwrite=true \
-X POST -H "Content-Type: application/json" \
-d '{"status":"inactive","trigger":null,"action":null}'
Packages
To create an action in a package you have to create a package first, to
create a package with name iot send an HTTP request with a PUT
method
curl -u $AUTH https://$APIHOST/api/v1/namespaces/_/packages/iot?overwrite=true \
-X PUT -H "Content-Type: application/json" \
-d '{"namespace":"_","name":"iot"}'
To force delete a package that contains entities, set the force
parameter to true. Failure will return an error either for failure to
delete an action within the package or the package itself. The package
will not be attempted to be deleted until all actions are successfully
deleted.
curl -u $AUTH https://$APIHOST/api/v1/namespaces/_/packages/iot?force=true \
-X DELETE
Activations
To get the list of the last 3 activations use a HTTP request with a
GET method, passing the query parameter limit=3
curl -u $AUTH https://$APIHOST/api/v1/namespaces/_/activations?limit=3
To get all the details of an activation including results and logs, send
a HTTP request with a GET method passing the activation identifier as
a path parameter
curl -u $AUTH https://$APIHOST/api/v1/namespaces/_/activations/f81dfddd7156401a8a6497f2724fec7b
Limits
To get the limits set for a namespace (i.e. invocationsPerMinute,
concurrentInvocations, firesPerMinute, actionMemoryMax, actionLogsMax…)
curl -u $AUTH https://$APIHOST/api/v1/namespaces/_/limits
Note that the default system values are returned if no specific limits
are set for the user corresponding to the authenticated identity.
3.2.4 - Scheduler
Use the scheduler to invoke repetitive or one-shot actions
OpenServerless Operator offers the possibility to deploy a simple “scheduler” to invoke repetitive or one-shot OpenWhisk actions. For example, an action executing a SQL script to create a PostgreSQL Database or inserting reference data, or simply an action that sends notifications with an API call every day at the same time.
How to Activate the Scheduler
Using the ops CLI, you can enable the scheduler with the following command:
ops config enable --cron
# if OpenServerless is not yet deployed
ops setup devcluster
# alternatively if OpenServerless is already deployed
ops update apply
By default, the internal scheduler executes a job every minute that starts searching for OpenWhisk actions with special annotations.
How to Deploy a Repetitive Action
Let’s assume we want to deploy an OpenWhisk action to be executed every 30 minutes. Suppose it’s an action that simply prints something, like this:
def main(args):
print('Hello from a repeated action')
return {
'body': 'action invoked'
}
abd save it to a file called scheduled-action.py
To deploy the action and instruct OpenServerless to execute it every 30 minutes, issue the following command:
ops action create scheduled-action scheduled-action.py -a cron "*/30 * * * *"
So you can create the action in the usual way and at the end add -a cron yourCronExpression.
How to Deploy a One-Shot Execution Action
Now suppose we want to execute the same action scheduled-action.py only once.
To deploy an action and request a single execution automatically via the OpenServerless Scheduler, issue the following command:
ops action create scheduled-action scheduled-action.py -a autoexec true
If we now print activation logs with ops activation poll, we will see our action execution log:
Activation: 'scheduled' (ebd532139a464e9d9532139a46ae9d8a)
[
"2024-03-08T07:28:02.050739962Z stdout: Hello from a scheduled action"
]
The Scheduler executes the action according to the following rules:
Actions are called in a non-blocking fashion. To verify execution and logs, use the command ops activation list.
Actions are invoked without any parameters. It is advised to deploy actions with self-contained parameters.
3.2.5 - Runtimes under the hood
How to add new languages to your system
Adding Action Language Runtimes
OpenWhisk and OpenServerless supports several languages and
runtimes but there may be other languages or
runtimes that are important for your organization, and for which you
want tighter integration with the platform.
The platform is extensible and you can add new languages or runtimes
(with custom packages and third-party dependencies)
💡 NOTE
This guide describes the contract a runtime must satisfy. However all
the OpenServerless runtimes are implemented the using the ActionLoop
Proxy. This proxy is implemented in Go,
already satifies the semantic of a runtime ands makes very easy to build
a new runtime. You just need to provide “launcher code” in your favorite
programming language and a compilation script (generally written in
python) for the initialization of an action. You are advised to use it
for your own runtimes and use the material of this document as reference
for the behaviour of a runtime.
Runtime general requirements
The unit of execution for all functions is a Docker container which must implement a specific
Action interface that, in general performs:
Initialization - accepts an initialization
payload (the code) and prepared for execution,
Activation - accepts a runtime payload (the
input parameters) and
prepares the activation context,
runs the function,
returns the function result,
Logging - flushes all stdout and stderr logs
and adds a frame marker at the end of the activation.
The specifics of the Action interface and its
functions are shown below.
The runtimes manifest
Actions when created specify the desired runtime for the function via a
property called kind. When using the nuv CLI, this is specified as
--kind <runtime-kind>. The value is typically a string describing the
language (e.g., nodejs) followed by a colon and the version for the
runtime as in nodejs:20 or php:8.1.
The manifest is a map of runtime family names to an array of specific
kinds. As an example, the following entry add a new runtime family
called nodejs with a single kind nodejs:20.
{
"nodejs": [{
"kind": "nodejs:20",
"default": true,
"image": {
"prefix": "openwhisk",
"name": "action-nodejs-v20",
"tag": "latest"
}
}]
}
The default property indicates if the corresponding kind should be
treated as the default for the runtime family. The JSON image
structure defines the Docker image name that is used for actions of this
kind (e.g., openwhisk/nodejs10action:latest for the JSON example
above).
The test action
The standard test action is shown below in JavaScript. It should be
adapted for the new language and added to the test artifacts
directory with the name
<runtime-kind>.txt for plain text file or <runtime-kind>.bin for a a
binary file. The <runtime-kind> must match the value used for kind
in the corresponding runtime manifest entry, replacing : in the kind
with a -. For example, a plain text function for nodejs:20 becomes
nodejs-20.txt.
function main(args) {
var str = args.delimiter + " ☃ " + args.delimiter;
console.log(str);
return { "winter": str };
}
Action Interface
An action consists of the user function (and its dependencies) along
with a proxy that implements a canonical protocol to integrate with
the OpenWhisk and OpenServerless platform.
The proxy is a web server with two endpoints.
The proxy also prepares the execution context, and flushes the logs
produced by the function to stdout and stderr.
Initialization
The initialization route is /init. It must accept a POST request
with a JSON object as follows:
{
"value": {
"name" : String,
"main" : String,
"code" : String,
"binary": Boolean,
"env": Map[String, String]
}
}
name is the name of the action.
main is the name of the function to execute.
code is either plain text or a base64 encoded string for binary
functions (i.e., a compiled executable).
binary is false if code is in plain text, and true if code is
base64 encoded.
env is a map of key-value pairs of properties to export to the
environment. And contains several properties starting with the
__OW_ prefix that are specific to the running action.
__OW_API_KEY the API key for the subject invoking the action,
this key may be a restricted API key. This property is absent
unless explicitly
requested.
__OW_NAMESPACE the namespace for the activation (this may
not be the same as the namespace for the action).
__OW_ACTION_NAME the fully qualified name of the running
action.
__OW_ACTION_VERSION the internal version number of the running
action.
__OW_ACTIVATION_ID the activation id for this running action
instance.
__OW_DEADLINE the approximate time when this initializer will
have consumed its entire duration quota (measured in epoch
milliseconds).
The initialization route is called exactly once by the OpenWhisk and
OpenServerless platform, before executing a function. The route should report
an error if called more than once. It is possible however that a single
initialization will be followed by many activations (via /run). If an
env property is provided, the corresponding environment variables
should be defined before the action code is initialized.
Successful initialization: The route should respond with 200 OK if
the initialization is successful and the function is ready to execute.
Any content provided in the response is ignored.
Failures to initialize: Any response other than 200 OK is treated
as an error to initialize. The response from the handler if provided
must be a JSON object with a single field called error describing the
failure. The value of the error field may be any valid JSON value. The
proxy should make sure to generate meaningful log message on failure to
aid the end user in understanding the failure.
Time limit: Every action in OpenWhisk and OpenServerless has a defined
time limit (e.g., 60 seconds). The initialization must complete within
the allowed duration. Failure to complete initialization within the
allowed time frame will destroy the container.
Limitation: The proxy does not currently receive any of the
activation context at initialization time. There are scenarios where the
context is convenient if present during initialization. This will
require a change in the OpenWhisk and OpenServerless platform itself. Note
that even if the context is available during initialization, it must be
reset with every new activation since the information will change with
every execution.
Activation
The proxy is ready to execute a function once it has successfully
completed initialization. The OpenWhisk and OpenServerless platform will
invoke the function by posting an HTTP request to /run with a JSON
object providing a new activation context and the input parameters for
the function. There may be many activations of the same function against
the same proxy (viz. container). Currently, the activations are
guaranteed not to overlap — that is, at any given time, there is at most
one request to /run from the OpenWhisk and OpenServerless platform.
The route must accept a JSON object and respond with a JSON object,
otherwise the OpenWhisk and OpenServerless platform will treat the activation
as a failure and proceed to destroy the container. The JSON object
provided by the platform follows the following schema:
{
"value": JSON,
"namespace": String,
"action_name": String,
"api_host": String,
"api_key": String,
"activation_id": String,
"transaction_id": String,
"deadline": Number
}
value is a JSON object and contains all the parameters for the
function activation.
namespace is the OpenWhisk and OpenServerless namespace for the action
(e.g., whisk-system).
action_name is the fully qualified
name of the action.
activation_id is a unique ID for this activation.
transaction_id is a unique ID for the request of which this
activation is part of.
deadline is the deadline for the function.
api_key is the API key used to invoke the action.
The value is the function parameters. The rest of the properties
become part of the activation context which is a set of environment
variables constructed by capitalizing each of the property names, and
prefixing the result with __OW_. Additionally, the context must define
__OW_API_HOST whose value is the OpenWhisk and OpenServerless API host.
This value is currently provided as an environment variable defined at
container startup time and hence already available in the context.
Successful activation: The route must respond with 200 OK if the
activation is successful and the function has produced a JSON object as
its result. The response body is recorded as the result of the
activation.
Failed activation: Any response other than 200 OK is treated as an
activation error. The response from the handler must be a JSON object
with a single field called error describing the failure. The value of
the error field may be any valid JSON value. Should the proxy fail to
respond with a JSON object, the OpenWhisk and OpenServerless platform will
treat the failure as an uncaught exception. These two failures modes are
distinguished by the value of the response.status in the activation
record which is application error if the proxy returned an error
object, and action developer error otherwise.
Time limit: Every action in OpenWhisk and OpenServerless has a defined
time limit (e.g., 60 seconds). The activation must complete within the
allowed duration. Failure to complete activation within the allowed time
frame will destroy the container.
Logging
The proxy must flush all the logs produced during initialization and
execution and add a frame marker to denote the end of the log stream for
an activation. This is done by emitting the token
XXX_THE_END_OF_A_WHISK_ACTIVATION_XXX as the last log line for the
stdout and stderr streams. Failure to emit this marker will cause
delayed or truncated activation logs.
Testing
Action Interface tests
The Action interface is enforced via a canonical
test suite which validates the initialization protocol, the runtime
protocol, ensures the activation context is correctly prepared, and that
the logs are properly framed. Your runtime should extend this test
suite, and of course include additional tests as needed.
Runtime proxy tests
The tests verify that the proxy can handle the following scenarios:
Test the proxy can handle the identity functions (initialize and
run).
Test the proxy can handle pre-defined environment variables as well
as initialization parameters.
Test the proxy properly constructs the activation context.
Test the proxy can properly handle functions with Unicode
characters.
Test the proxy can handle large payloads (more than 1MB).
Test the proxy can handle an entry point other than main.
Test the proxy does not permit re-initialization.
Test the error handling for an action returning an invalid response.
Test the proxy when initialized with no content.
The canonical test suite should be extended by the new runtime tests.
Additional tests will be required depending on the feature set provided
by the runtime.
Since the OpenWhisk and OpenServerless platform is language and runtime
agnostic, it is generally not necessary to add integration tests. That
is the unit tests verifying the protocol are sufficient. However, it may
be necessary in some cases to modify the ops CLI or other OpenWhisk
and OpenServerless clients. In which case, appropriate tests should be added
as necessary. The OpenWhisk and OpenServerless platform will perform a
generic integration test as part of its basic system tests. This
integration test will require a test function to be
available so that the test harness can create, invoke, and delete the
action.
3.2.6 - Building your runtime
How to implement your runtime from scratch
Developing a new Runtime with the ActionLoop proxy
The OpenWhisk and OpenServerless runtime specification
defines the expected behavior of an OpenWhisk and OpenServerless runtime; you
can choose to implement a new runtime from scratch by just following
this specification. However, the fastest way to develop a new, compliant
runtime is by reusing the ActionLoop
proxy
which already implements most of the specification and requires you to
write code for just a few hooks to get a fully functional (and fast)
runtime in a few hours or less.
What is the ActionLoop proxy
The ActionLoop proxy is a runtime “engine”, written in the Go
programming language, originally developed
specifically to support the OpenWhisk and OpenServerless Go language
runtime. However, it
was written in a generic way such that it has since been adopted to
implement OpenWhisk and OpenServerless runtimes for Swift, PHP, Python, Rust,
Java, Ruby and Crystal. Even though it was developed with compiled
languages in mind it works equally well with scripting languages.
Using it, you can develop a new runtime in a fraction of the time needed
for authoring a full-fledged runtime from scratch. This is due to the
fact that you have only to write a command line protocol and not a
fully-featured web server (with a small amount of corner cases to
consider). The results should also produce a runtime that is fairly fast
and responsive. In fact, the ActionLoop proxy has also been adopted to
improve the performance of existing runtimes like Python, Ruby, PHP, and
Java where performance has improved by a factor between 2x to 20x.
Precompilation of OpenWhisk and OpenServerless Actions
In addition to being the basis for new runtime development, ActionLoop
runtimes can also support offline “precompilation” of OpenWhisk and
OpenServerless Action source files into a ZIP file that contains only the
compiled binaries which are very fast to start once deployed. More
information on this approach can be found here: Precompiling Go Sources
Offline
which describes how to do this for the Go language, but the approach
applies to any language supported by ActionLoop.
Tutorial - How to write a new runtime with the ActionLoop Proxy
This section contains a stepwise tutorial which will take you through
the process of developing a new ActionLoop runtime using the Ruby
language as the example.
General development process
The general procedure for authoring a runtime with the
ActionLoop proxy requires the following steps:
building a docker image containing your target language compiler and
the ActionLoop runtime.
writing a simple line-oriented protocol in your target language.
writing a compilation script for your target language.
writing some mandatory tests for your language.
ActionLoop Starter Kit
To facilitate the process, there is an actionloop-starter-kit in the
openwhisk-devtools
GitHub repository, that implements a fully working runtime for Python.
It contains a stripped-down version of the real Python runtime (with
some advanced features removed) along with guided, step-by-step
instructions on how to translate it to a different target runtime
language using Ruby as an example.
In short, the starter kit provides templates you can adapt in creating
an ActionLoop runtime for each of the steps listed above, these include
:
-checking out the actionloop-starter-kit from the openwhisk-devtools
repository -editing the Dockerfile to create the target environment
for your target language. -converting (rewrite) the launcher.py script
to an equivalent for script for your target language. -editing the
compile script to compile your action in your target language.
-writing the mandatory tests for your target language, by adapting the
ActionLoopPythonBasicTests.scala file.
As a starting language, we chose Python since it is one of the more
human-readable languages (can be treated as pseudo-code). Do not
worry, you should only need just enough Python knowledge to be able to
rewrite launcher.py and edit the compile script for your target
language.
Finally, you will need to update the ActionLoopPythonBasicTests.scala
test file which, although written in the Scala language, only serves as
a wrapper that you will use to embed your target language tests into.
Notation
In each step of this tutorial, we typically show snippets of either
terminal transcripts (i.e., commands and results) or “diffs” of changes
to existing code files.
Within terminal transcript snippets, comments are prefixed with #
character and commands are prefixed by the $ character. Lines that
follow commands may include sample output (from their execution) which
can be used to verify against results in your local environment.
When snippets show changes to existing source files, lines without a
prefix should be left “as is”, lines with - should be removed and
lines with + should be added.
Prerequisites
# Verify docker version
$ docker --version
Docker version 18.09.3
# Verify docker is running
$ docker ps
# The result should be a valid response listing running processes
Setup the development directory
So let’s start to create our own actionloop-demo-ruby-2.6 runtime.
First, check out the devtools repository to access the starter kit,
then move it in your home directory to work on it.
git clone https://github.com/apache/openwhisk-devtools
mv openwhisk-devtools/actionloop-starter-kit ~/actionloop-demo-ruby-v2.6
Now, take the directory python3.7 and rename it to ruby2.6 and use
sed to fix the directory name references in the Gradle build files.
cd ~/actionloop-demo-ruby-v2.6
mv python3.7 ruby2.6
sed -i.bak -e 's/python3.7/ruby2.6/' settings.gradle
sed -i.bak -e 's/actionloop-demo-python-v3.7/actionloop-demo-ruby-v2.6/' ruby2.6/build.gradle
Let’s check everything is fine building the image.
# building the image
$ ./gradlew distDocker
# ... intermediate output omitted ...
BUILD SUCCESSFUL in 1s
2 actionable tasks: 2 executed
# checking the image is available
$ docker images actionloop-demo-ruby-v2.6
REPOSITORY TAG IMAGE ID CREATED SIZE
actionloop-demo-ruby-v2.6 latest df3e77c9cd8f 2 minutes ago 94.3MB
At this point, we have built a new image named
actionloop-demo-ruby-v2.6. However, despite having Ruby in the name,
internally it still is a Python language runtime which we will need to
change to one supporting Ruby as we continue in this tutorial.
Preparing the Docker environment
Our language runtime’s Dockerfile has the task of preparing an
environment for executing OpenWhisk and OpenServerless Actions. Using the
ActionLoop approach, we use a multistage Docker build to
derive our OpenWhisk and OpenServerless language runtime from an existing
Docker image that has all the target language’s tools and libraries
for running functions authored in that language.
leverage the existing openwhisk/actionlooop-v2 image on Docker Hub
from which we will “extract” the ActionLoop proxy (i.e. copy
/bin/proxy binary) our runtime will use to process Activation
requests from the OpenWhisk and OpenServerless platform and execute
Actions by using the language’s tools and libraries from step #1.
Repurpose the renamed Python Dockerfile for Ruby builds
Let’s edit the ruby2.6/Dockerfile to use the official Ruby image on
Docker Hub as our base image, instead of a Python image, and add our our
Ruby launcher script:
FROM openwhisk/actionloop-v2:latest as builder
-FROM python:3.7-alpine
+FROM ruby:2.6.2-alpine3.9
RUN mkdir -p /proxy/bin /proxy/lib /proxy/action
WORKDIR /proxy
COPY --from=builder /bin/proxy /bin/proxy
-ADD lib/launcher.py /proxy/lib/launcher.py
+ADD lib/launcher.rb /proxy/lib/launcher.rb
ADD bin/compile /proxy/bin/compile
+RUN apk update && apk add python3
ENV OW_COMPILER=/proxy/bin/compile
ENTRYPOINT ["/bin/proxy"]
Next, let’s rename the launcher.py (a Python script) to one that
indicates it is a Ruby script named launcher.rb.
mv ruby2.6/lib/launcher.py ruby2.6/lib/launcher.rb
Note that:
You changed the base Docker image to use a Ruby language image.
You changed the launcher script from Python to Ruby.
We had to add a python3 package to our Ruby image since our
compile script will be written in Python for this tutorial. Of
course, you may choose to rewrite the compile script in Ruby if
you wish to as your own exercise.
Implementing the ActionLoop protocol
This section will take you through how to convert the contents of
launcher.rb (formerly launcher.py) to the target Ruby programming
language and implement the ActionLoop protocol.
What the launcher needs to do
Let’s recap the steps the launcher must accomplish to implement the
ActionLoop protocol :
import the Action function’s main method for execution.
- Note: the
compile script will make the function available to
the launcher.
open the system’s file descriptor 3 which will be used to output
the functions response.
read the system’s standard input, stdin, line-by-line. Each line
is parsed as a JSON string and produces a JSON object (not an array
nor a scalar) to be passed as the input arg to the function.
- Note: within the JSON object, the
value key contains the user
parameter data to be passed to your functions. All the other
keys are made available as process environment variables to the
function; these need to be uppercased and prefixed with
"__OW_".
invoke the main function with the JSON object payload.
encode the result of the function in JSON (ensuring it is only one
line and it is terminated with one newline) and write it to
file descriptor 3.
Once the function returns the result, flush the contents of
stdout, stderr and file descriptor 3 (FD 3).
Finally, include the above steps in a loop so that it continually
looks for Activations. That’s it.
Converting launcher script to Ruby
Now, let’s look at the protocol described above, codified within the
launcher script launcher.rb, and work to convert its contents from
Python to Ruby.
Import the function code
Skipping the first few library import statements within launcer.rb,
which we will have to resolve later after we determine which ones Ruby
may need, we see the first significant line of code importing the actual
Action function.
# now import the action as process input/output
from main__ import main as main
In Ruby, this can be rewritten as:
# requiring user's action code
require "./main__"
Note that you are free to decide the path and filename for the
function’s source code. In our examples, we chose a base filename that
includes the word "main" (since it is OpenWhisk and OpenServerless
default function name) and append two underscores to better assure
uniqueness.
Open File Descriptor (FD) 3 for function results output
The ActionLoop proxy expects to read the results of invoking the
Action function from File Descriptor (FD) 3.
The existing Python:
out = fdopen(3, "wb")
would be rewritten in Ruby as:
out = IO.new(3)
Process Action’s arguments from STDIN
Each time the function is invoked via an HTTP request, the ActionLoop
proxy passes the message contents to the launcher via STDIN. The
launcher must read STDIN line-by-line and parse it as JSON.
The launcher’s existing Python code reads STDIN line-by-line as
follows:
while True:
line = stdin.readline()
if not line: break
# ...continue...
would be translated to Ruby as follows:
while true
# JSON arguments get passed via STDIN
line = STDIN.gets()
break unless line
# ...continue...
end
Each line is parsed in JSON, where the payload is extracted from
contents of the "value" key. Other keys and their values are as
uppercased, "__OW_" prefixed environment variables:
The existing Python code for this is:
# ... continuing ...
args = json.loads(line)
payload = {}
for key in args:
if key == "value":
payload = args["value"]
else:
os.environ["__OW_%s" % key.upper()]= args[key]
# ... continue ...
would be translated to Ruby:
# ... continuing ...
args = JSON.parse(line)
payload = {}
args.each do |key, value|
if key == "value"
payload = value
else
# set environment variables for other keys
ENV["__OW_#{key.upcase}"] = value
end
end
# ... continue ...
Invoking the Action function
We are now at the point of invoking the Action function and producing
its result. Note we must also capture exceptions and produce an
{"error": <result> } if anything goes wrong during execution.
The existing Python code for this is:
# ... continuing ...
res = {}
try:
res = main(payload)
except Exception as ex:
print(traceback.format_exc(), file=stderr)
res = {"error": str(ex)}
# ... continue ...
would be translated to Ruby:
# ... continuing ...
res = {}
begin
res = main(payload)
rescue Exception => e
puts "exception: #{e}"
res ["error"] = "#{e}"
end
# ... continue ...
Finalize File Descriptor (FD) 3, STDOUT and STDERR
Finally, we need to write the function’s result to File Descriptor (FD)
3 and “flush” standard out (stdout), standard error (stderr) and FD 3.
The existing Python code for this is:
out.write(json.dumps(res, ensure_ascii=False).encode('utf-8'))
out.write(b'\n')
stdout.flush()
stderr.flush()
out.flush()
would be translated to Ruby:
STDOUT.flush()
STDERR.flush()
out.puts(res.to_json)
out.flush()
Congratulations! You just completed your ActionLoop request handler.
Writing the compilation script
Now, we need to write the compilation script. It is basically a script
that will prepare the uploaded sources for execution, adding the
launcher code and generate the final executable.
For interpreted languages, the compilation script will only “prepare”
the sources for execution. The executable is simply a shell script to
invoke the interpreter.
For compiled languages, like Go it will actually invoke a compiler in
order to produce the final executable. There are also cases like Java
where we still need to execute the compilation step that produces
intermediate code, but the executable is just a shell script that will
launch the Java runtime.
How the ActionLoop proxy handles action uploads
The OpenWhisk and OpenServerless user can upload actions with the ops
Command Line Interface (CLI) tool as a single file.
This single file can be:
Important: an executable for ActionLoop is either a Linux binary (an
ELF executable) or a script. A script is, using Linux conventions, is
anything starting with #!. The first line is interpreted as the
command to use to launch the script: #!/bin/bash, #!/usr/bin/python
etc.
The ActionLoop proxy accepts any file, prepares a work folder, with two
folders in it named "src" and "bin". Then it detects the format of
the uploaded file. For each case, the behavior is different.
If the uploaded file is an executable, it is stored as bin/exec
and executed.
If the uploaded file is not an executable and not a zip file, it is
stored as src/exec then the compilation script is invoked.
If the uploaded file is a zip file, it is unzipped in the src
folder, then the src/exec file is checked.
If it exists and it is an executable, the folder src is renamed to
bin and then again the bin/exec is executed.
If the src/exec is missing or is not an executable, then the
compiler script is invoked.
The compilation script is invoked only when the upload contains sources.
According to the description in the past paragraph, if the upload is a
single file, we can expect the file is in src/exec, without any
prefix. Otherwise, sources are spread the src folder and it is the
task of the compiler script to find the sources. A runtime may impose
that when a zip file is uploaded, then there should be a fixed file with
the main function. For example, the Python runtime expects the file
__main__.py. However, it is not a rule: the Go runtime does not
require any specific file as it compiles everything. It only requires a
function with the name specified.
The compiler script goal is ultimately to leave in bin/exec an
executable (implementing the ActionLoop protocol) that the proxy can
launch. Also, if the executable is not standalone, other files must be
stored in this folder, since the proxy can also zip all of them and send
to the user when using the pre-compilation feature.
The compilation script is a script pointed by the OW_COMPILER
environment variable (you may have noticed it in the Dockerfile) that
will be invoked with 3 parameters:
<main> is the name of the main function specified by the user on
the ops command line
<src> is the absolute directory with the sources already unzipped
an empty <bin> directory where we are expected to place our final
executables
Note that both the <src> and <bin> are disposable, so we can do
things like removing the <bin> folder and rename the <src>.
Since the user generally only sends a function specified by the <main>
parameter, we have to add the launcher we wrote and adapt it to execute
the function.
Implementing the compile for Ruby
This is the algorithm that the compile script in the kit follows for
Python:
if there is a <src>/exec it must rename to the main file; I use
the name main__.py
if there is a <src>/__main__.py it will rename to the main file
main__.py
copy the launcher.py to exec__.py, replacing the main(arg)
with <main>(arg); this file imports the main__.py and invokes
the function <main>
add a launcher script <src>/exec
finally it removes the <bin> folder and rename <src> to <bin>
We can adapt this algorithm easily to Ruby with just a few changes.
The script defines the functions sources and build then starts the
execution, at the end of the script.
Start from the end of the script, where the script collect parameters
from the command line. Instead of launcher.py, use launcher.rb:
- launcher = "%s/lib/launcher.py" % dirname(dirname(sys.argv[0]))
+ launcher = "%s/lib/launcher.rb" % dirname(dirname(sys.argv[0]))
Then the script invokes the source function. This function renames the
exec file to main__.py, you will rename it instead to main__.rb:
- copy_replace(src_file, "%s/main__.py" % src_dir)
+ copy_replace(src_file, "%s/main__.rb" % src_dir)
If instead there is a __main__.py the function will rename to
main__.py (the launcher invokes this file always). The Ruby runtime
will use a main.rb as starting point. So the next change is:
- # move __main__ in the right place if it exists
- src_file = "%s/__main__.py" % src_dir
+ # move main.rb in the right place if it exists
+ src_file = "%s/main.rb" % src_dir
Now, the source function copies the launcher as exec__.py, replacing
the line from main__ import main as main (invoking the main function)
with from main__ import <main> as main. In Ruby you may want to
replace the line res = main(payload) with res = <main>(payload). In
code it is:
- copy_replace(launcher, "%s/exec__.py" % src_dir,
- "from main__ import main as main",
- "from main__ import %s as main" % main )
+ copy_replace(launcher, "%s/exec__.rb" % src_dir,
+ "res = main(payload)",
+ "res = %s(payload)" % main )
We are almost done. We just need the startup script that instead of
invoking python will invoke Ruby. So in the build function do this
change:
write_file("%s/exec" % tgt_dir, """#!/bin/sh
cd "$(dirname $0)"
-exec /usr/local/bin/python exec__.py
+exec ruby exec__.rb
""")
For an interpreted language that is all. We move the src folder in the
bin. For a compiled language instead, we may want to actually invoke
the compiler to produce the executable.
Debugging
Now that we have completed both the launcher and compile scripts, it
is time to test them.
Here we will learn how to:
enter in a test environment
simple smoke tests to check things work
writing the validation tests
testing the image in an actual OpenWhisk and OpenServerless environment
Entering in the test environment
In the starter kit, there is a Makefile that can help with our
development efforts.
We can build the Dockerfile using the provided Makefile. Since it has a
reference to the image we are building, let’s change it:
sed -i.bak -e 's/actionloop-demo-python-v3.7/actionloop-demo-ruby-v2.6/' ruby2.6/Makefile
We should be now able to build the image and enter in it with
make debug. It will rebuild the image for us and put us into a shell
so we can enter access the image environment for testing and debugging:
$ cd ruby2.6
$ make debug
# results omitted for brevity ...
Let’s start with a couple of notes about this test environment.
First, use --entrypoint=/bin/sh when starting the image to have a
shell available at our image entrypoint. Generally, this is true by
default; however, in some stripped down base images a shell may not be
available.
Second, the /proxy folder is mounted in our local directory, so that
we can edit the bin/compile and the lib/launcher.rb using our editor
outside the Docker image
NOTE It is not necessary to rebuild the Docker image with every change
when using make debug since directories and environment variables used
by the proxy indicate where the code outside the Docker container is
located.
Once at the shell prompt that we will use for development, we will have
to start and stop the proxy. The shell will help us to inspect what
happened inside the container.
A simple smoke test
It is time to test. Let’s write a very simple test first, converting the
example\hello.py in example\hello.rb to appear as follows:
def hello(args)
name = args["name"] || "stranger"
greeting = "Hello #{name}!"
puts greeting
{ "greeting" => greeting }
end
Now change into the ruby2.6 subdirectory of our runtime project and in
one terminal type:
$ cd <projectdir>/ruby2.6
$ make debug
# results omitted for brevity ...
# (you should see a shell prompt of your image)
$ /bin/proxy -debug
2019/04/08 07:47:36 OpenWhisk and OpenServerless ActionLoop Proxy 2: starting
Now the runtime is started in debug mode, listening on port 8080, and
ready to accept Action deployments.
Open another terminal (while leaving the first one running the proxy)
and go into the top-level directory of our project to test the Action
by executing an init and then a couple of run requests using the
tools/invoke.py test script.
These steps should look something like this in the second terminal:
$ cd <projectdir>
$ python tools/invoke.py init hello example/hello.rb
{"ok":true}
$ python tools/invoke.py run '{}'
{"greeting":"Hello stranger!"}
$ python tools/invoke.py run '{"name":"Mike"}'
{"greeting":"Hello Mike!"}
We should also see debug output from the first terminal running the
proxy (with the debug flag) which should have successfully processed
the init and run requests above.
The proxy’s debug output should appear something like:
/proxy # /bin/proxy -debug
2019/04/08 07:54:57 OpenWhisk and OpenServerless ActionLoop Proxy 2: starting
2019/04/08 07:58:00 compiler: /proxy/bin/compile
2019/04/08 07:58:00 it is source code
2019/04/08 07:58:00 compiling: ./action/16/src/exec main: hello
2019/04/08 07:58:00 compiling: /proxy/bin/compile hello action/16/src action/16/bin
2019/04/08 07:58:00 compiler out: , <nil>
2019/04/08 07:58:00 env: [__OW_API_HOST=]
2019/04/08 07:58:00 starting ./action/16/bin/exec
2019/04/08 07:58:00 Start:
2019/04/08 07:58:00 pid: 13
2019/04/08 07:58:24 done reading 13 bytes
Hello stranger!
XXX_THE_END_OF_A_WHISK_ACTIVATION_XXX
XXX_THE_END_OF_A_WHISK_ACTIVATION_XXX
2019/04/08 07:58:24 received::{"greeting":"Hello stranger!"}
2019/04/08 07:58:54 done reading 27 bytes
Hello Mike!
XXX_THE_END_OF_A_WHISK_ACTIVATION_XXX
XXX_THE_END_OF_A_WHISK_ACTIVATION_XXX
2019/04/08 07:58:54 received::{"greeting":"Hello Mike!"}
Hints and tips for debugging
Of course, it is very possible something went wrong. Here a few
debugging suggestions:
The ActionLoop runtime (proxy) can only be initialized once using the
init command from the invoke.py script. If we need to re-initialize
the runtime, we need to stop the runtime (i.e., with Control-C) and
restart it.
We can also check what is in the action folder. The proxy creates a
numbered folder under action and then a src and bin folder.
For example, using a terminal window, we would would see a directory and
file structure created by a single action:
$ find
action/
action/1
action/1/bin
action/1/bin/exec__.rb
action/1/bin/exec
action/1/bin/main__.rb
Note that the exec starter, exec__.rb launcher and main__.rb
action code are have all been copied under a directory numbered`1`.
In addition, we can try to run the action directly and see if it behaves
properly:
$ cd action/1/bin
$ ./exec 3>&1
$ {"value":{"name":"Mike"}}
Hello Mike!
{"greeting":"Hello Mike!"}
Note we redirected the file descriptor 3 in stdout to check what is
happening, and note that logs appear in stdout too.
Also, we can test the compiler invoking it directly.
First let’s prepare the environment as it appears when we just uploaded
the action:
$ cd /proxy
$ mkdir -p action/2/src action/2/bin
$ cp action/1/bin/main__.rb action/2/src/exec
$ find action/2
action/2
action/2/bin
action/2/src
action/2/src/exec
Now compile and examine the results again:
$ /proxy/bin/compile main action/2/src action/2/bin
$ find action/2
action/2/
action/2/bin
action/2/bin/exec__.rb
action/2/bin/exec
action/2/bin/main__.rb
Testing
If we have reached this point in the tutorial, the runtime is able to
run and execute a simple test action. Now we need to validate the
runtime against a set of mandatory tests both locally and within an
OpenWhisk and OpenServerless staging environment. Additionally, we should
author and automate additional tests for language specific features and
styles.
The starter kit includes two handy makefiles that we can leverage
for some additional tests. In the next sections, we will show how to
update them for testing our Ruby runtime.
Testing multi-file Actions
So far we tested a only an Action comprised of a single file. We should
also test multi-file Actions (i.e., those with relative imports) sent to
the runtime in both source and binary formats.
First, let’s try a multi-file Action by creating a Ruby Action script
named example/main.rb that invokes our hello.rb as follows:
require "./hello"
def main(args)
hello(args)
end
Within the example/Makefile makefile:
-IMG=actionloop-demo-python-v3.7:latest
-ACT=hello-demo-python
-PREFIX=docker.io/openwhisk
+IMG=actionloop-demo-ruby-v2.6:latest
+ACT=hello-demo-ruby
+PREFIX=docker.io/<docker username>
Now, we are ready to test the various cases. Again, start the runtime
proxy in debug mode:
cd ruby2.6
make debug
/bin/proxy -debug
On another terminal, try to deploy a single file:
$ make test-single
python ../tools/invoke.py init hello ../example/hello.rb
{"ok":true}
python ../tools/invoke.py run '{}'
{"greeting":"Hello stranger!"}
python ../tools/invoke.py run '{"name":"Mike"}'
{"greeting":"Hello Mike!"}
Now, stop and restart the proxy and try to send a ZIP file with the
sources:
$ make test-src-zip
zip src.zip main.rb hello.rb
adding: main.rb (deflated 42%)
adding: hello.rb (deflated 42%)
python ../tools/invoke.py init ../example/src.zip
{"ok":true}
python ../tools/invoke.py run '{}'
{"greeting":"Hello stranger!"}
python ../tools/invoke.py run '{"name":"Mike"}'
{"greeting":"Hello Mike!"}
Finally, test the pre-compilation: the runtime builds a zip file with
the sources ready to be deployed. Again, stop and restart the proxy
then:
$ make test-bin-zip
docker run -i actionloop-demo-ruby-v2.6:latest -compile main <src.zip >bin.zip
python ../tools/invoke.py init ../example/bin.zip
{"ok":true}
python ../tools/invoke.py run '{}'
{"greeting":"Hello stranger!"}
python ../tools/invoke.py run '{"name":"Mike"}'
{"greeting":"Hello Mike!"}
Congratulations! The runtime works locally! Time to test it on the
public cloud. So as the last step before moving forward, let’s push the
image to Docker Hub with make push.
Testing on OpenWhisk and OpenServerless
To run this test you need to configure access to OpenWhisk and OpenServerless
with ops. A simple way is to get access is to register a free account
in the IBM Cloud but this works also with our own deployment of
OpenWhisk and OpenServerless.
Edit the Makefile as we did previously:
IMG=actionloop-demo-ruby-v2.6:latest
ACT=hello-demo-ruby
PREFIX=docker.io/<docker username>
Also, change any reference to hello.py and main.py to hello.rb and
main.rb.
Once this is done, we can re-run the tests we executed locally on “the
real thing”.
Test single:
$ make test-single
ops action update hello-demo-ruby hello.rb --docker docker.io/linus/actionloop-demo-ruby-v2.6:latest --main hello
ok: updated action hello-demo-ruby
ops action invoke hello-demo-ruby -r
{
"greeting": "Hello stranger!"
}
ops action invoke hello-demo-ruby -p name Mike -r
{
"greeting": "Hello Mike!"
}
Test source zip:
$ make test-src-zip
zip src.zip main.rb hello.rb
adding: main.rb (deflated 42%)
adding: hello.rb (deflated 42%)
ops action update hello-demo-ruby src.zip --docker docker.io/linus/actionloop-demo-ruby-v2.6:latest
ok: updated action hello-demo-ruby
ops action invoke hello-demo-ruby -r
{
"greeting": "Hello stranger!"
}
ops action invoke hello-demo-ruby -p name Mike -r
{
"greeting": "Hello Mike!"
}
Test binary ZIP:
$ make test-bin-zip
docker run -i actionloop-demo-ruby-v2.6:latest -compile main <src.zip >bin.zip
ops action update hello-demo-ruby bin.zip --docker docker.io/actionloop/actionloop-demo-ruby-v2.6:latest
ok: updated action hello-demo-ruby
ops action invoke hello-demo-ruby -r
{
"greeting": "Hello stranger!"
}
ops action invoke hello-demo-ruby -p name Mike -r
{
"greeting": "Hello Mike!"
}
Congratulations! Your runtime works also in the real world.
Writing the validation tests
Before you can submit your runtime you should ensure your runtime pass
the validation tests.
Under
tests/src/test/scala/runtime/actionContainers/ActionLoopPythonBasicTests.scala
there is the template for the test.
Rename to
tests/src/test/scala/runtime/actionContainers/ActionLoopRubyBasicTests.scala,
change internally the class name to class ActionLoopRubyBasicTests and
implement the following test cases:
You should convert Python code to Ruby code. We do not do go into the
details of each test, as they are pretty simple and obvious. You can
check the source code for the real test
here.
You can verify tests are running properly with:
$ ./gradlew test
Starting a Gradle Daemon, 1 busy Daemon could not be reused, use --status for details
> Task :tests:test
runtime.actionContainers.ActionLoopPythoRubyTests > runtime proxy should handle initialization with no code PASSED
runtime.actionContainers.ActionLoopPythoRubyTests > runtime proxy should handle initialization with no content PASSED
runtime.actionContainers.ActionLoopPythoRubyTests > runtime proxy should run and report an error for function not returning a json object PASSED
runtime.actionContainers.ActionLoopPythoRubyTests > runtime proxy should fail to initialize a second time PASSED
runtime.actionContainers.ActionLoopPythoRubyTests > runtime proxy should invoke non-standard entry point PASSED
runtime.actionContainers.ActionLoopPythoRubyTests > runtime proxy should echo arguments and print message to stdout/stderr PASSED
runtime.actionContainers.ActionLoopPythoRubyTests > runtime proxy should handle unicode in source, input params, logs, and result PASSED
runtime.actionContainers.ActionLoopPythoRubyTests > runtime proxy should confirm expected environment variables PASSED
runtime.actionContainers.ActionLoopPythoRubyTests > runtime proxy should echo a large input PASSED
BUILD SUCCESSFUL in 55s
Big congratulations are in order having reached this point successfully.
At this point, our runtime should be ready to run on any OpenWhisk and
OpenServerless platform and also can be submitted for consideration to be
included in the Apache OpenWhisk and OpenServerless project.
3.3 - Runtimes
List of OpenServerless’ supported runtimes
Supported Runtimes
This document is still 🚧 work in progress 🚧
The programming languages currently directly supported by OpenServerless are:
3.4 - Tasks
Type ops <task> to see usage and subtasks.
OpenServerless Administration Tasks
admin Manage additional users in OpenServerless
config Manage the Apache OpenServerless configuration
setup Setup the Apache OpenServerless platform on multiple environments
debug Debug utilities for the Apache OpenServerless platform
cloud OpenServerless setup utilities for supported Deployment models on Cloud Providers
util Utilities
OpenServerless Development Tasks
ide OpenServerless Development Utilities
OpenWhisk Tasks
action Manage actions
invoke Invoke an action (pass parameters with <key>=<value>)
url Get the url of an action
activations Manage activations
logs Show logs of activations
result Show results of activations
package Manage packages
trigger Manage triggers
rule Manage rules for triggers
3.4.1 - Admin
Administer OpenServerless users.
Synopsis
In OpenServerless, users are namespaces.
You can create namespaces and choose which services to enable.
Usage:
admin adduser <username> <email> <password> [--all] [--redis] [--mongodb] [--minio] [--postgres] [--storagequota=<quota>|auto]
admin deleteuser <username>
Commands
admin adduser create a new user in OpenServerless with the username, email and password provided
admin deleteuser delete a user from the OpenServerless installation via the username provided
Options
--all enable all services
--redis enable redis
--mongodb enable mongodb
--minio enable minio
--postgres enable postgres
--storagequota=<quota>
3.4.2 - Cloud
Administer cloud and baremetal infrastructure
OpenServerless Cloud Administration Tasks
Administer deploy of various kubernetes cluster on different cloud providers
or virtual machines or bare metal.
aks Azure AKS subcommands
aws Amazon Web Services subcommands
azcloud Azure Cloud subcommands
eks Amazon Web Services - EKS subcommands
gcloud Google Cloud subcommands
gke Google Cloud - GKE subcommands
k3s Rancher K3S subcommands
mk8s Ubuntu MicroK8s subcommands
osh RedHat OpenShift subcommands
3.4.2.1 - Aks
Create and Manage an Azure AKS cluster
Synopsis
Usage:
aks config
aks create
aks delete
aks kubeconfig
aks lb
aks status
Commands
config configure an Azure AKS kubernetes cluster
create create an Azure AKS kubernetes cluster
delete delete the current Azure AKS cluster
kubeconfig extract the kubeconfig to access
lb show the load balancer
prereq check prerequisites
status show the cluster status
3.4.2.2 - Aws
Create and Manage an Amazon Virtual Machines and Dns Zones
Synopsis
Usage:
aws vm-list
aws vm-create <name>
aws vm-delete <name>
aws vm-getip <name>
aws zone-create <zone>
aws zone-delete <zone>
aws zone-list [<zone>]
aws zone-update <zone> (--host=<host>|--wildcard) (--vm=<vm>|--ip=<ip>|--cname=<cname>)
Commands
Commands:
vm-list lists the vm and their ips
vm-create create a vm
vm-getip get ip
vm-delete delete the vm
zone-create create a zone - you will have to delegate the zone
from the parent zone assigning the nameservers
zone-delete delete a zone
zone-list list zones
zone-update update a zone with an ip, a cname or the ip of a vm
3.4.2.3 - Azcloud
Manage Azure Virtual Machines and DNS Zones
Synopsis
Usage:
azcloud vm-list
azcloud vm-ip <name>
azcloud vm-create <name>
azcloud vm-delete <name>
azcloud vm-getip <name>
azcloud zone-create <zone>
azcloud zone-delete <zone>
azcloud zone-list [<zone>]
azcloud zone-update <zone> (--host=<host>|--wildcard) (--vm=<vm>|--ip=<ip>|--cname=<cname>)
Commands
vm-ip create public ip
vm-list lists the vm and their ips
vm-create create a vm
vm-getip get ip
vm-delete delete the vm
zone-create create a zone - you will have to delegate the zone
from the parent zone assigning the nameservers
zone-delete delete a zone
zone-list list zones
zone-update update a zone with an ip, a cname or the ip of a vm
3.4.2.4 - Eks
Create and Manage an Amazon EKS cluster
Synopsis
Usage:
eks config
eks create
eks delete
eks kubeconfig
eks lb
eks status
Commands
config configure an Amazon EKS cluster
create create an Amazon EKS cluster
delete delete the current Amazon EKS cluster
kubeconfig extract kubeconfig for connecting to the cluster
lb show the load balancer hostname
prereq check prerequisites
status show the cluster status
3.4.2.5 - Gcloud
Create and Manage Google Virtual Machines
Synopsis
Usage:
gcloud vm-list
gcloud vm-create <name>
gcloud vm-delete <name>
gcloud vm-getip <name>
Commands
vm-list lists the vm and their ips
vm-create create a vm
vm-getip get ip
vm-delete delete the vm
3.4.2.6 - Gke
Create and Manage Google Kubernetes Engine cluster
Synopsis
Usage:
gke config
gke create
gke delete
gke kubeconfig
gke lb
Commands
config configure a Google Kubernetes Engine cluster
create create a Google Kubernetes Engine cluster
delete delete aks cluster
kubeconfig extract kubeconfig to access
lb show the load balancer
3.4.2.7 - K3s
Create and Manage K3S cluster
Synopsis
Usage:
k3s create <server> [<user>]
k3s delete <server> [<user>]
k3s info
k3s kubeconfig <server> [<user>]
k3s status
Commands
create create a k3s with ssh in <server> using <user> with sudo
delete uninstall k3s with ssh in <server> using <username> with sudo
info info on the server
kubeconfig recover the kubeconfig from a k3s server <server> with user <username>
status status of the server
3.4.2.8 - Mk8s
Create and Manage an mk8s kubernetes cluster
Synopsis
Usage:
mk8s create <server> [<user>]
mk8s delete <server> [<user>]
mk8s info
mk8s kubeconfig <server> [<user>]
mk8s status
Commands
create create a mk8s with ssh in <server> using <user> with sudo
delete uninstall microk8s with ssh in <server> using <user> with sudo
info info on the server
kubeconfig recover the kubeconfig from a server <server> with microk8s
status status of the server
3.4.2.9 - Osh
OpenShift configuration
Synopsis
Usage:
osh import <kubeconfig>
osh test <kubeconfig>
osh setup
3.4.3 - Config
Configure OpenServerless
Synopsis
Usage:
config (enable|disable) [--all] [--redis] [--mongodb] [--minio] [--cron] [--static] [--postgres] [--prometheus] [--slack] [--mail] [--affinity] [--tolerations] [--quota]
config apihost (<apihost>|auto) [--tls=<email>] [--protocol=<http/https>|auto]
config runtimes [<runtimesjson>]
config slack [--apiurl=<slackapiurl>] [--channel=<slackchannel>]
config mail [--mailuser=<mailuser>] [--mailpwd=<mailpwd>] [--mailfrom=<mailfrom>] [--mailto=<mailto>]
config volumes [--couchdb=<couchdb>] [--kafka=<kafka>] [--pgvol=<postgres>] [--storage=<storage>] [--alerting=<alerting>] [--zookeeper=<zookeeper>] [--redisvol=<redis>] [--mongogb=<mongodb>]
config controller [--javaopts=<javaopts>] [--loglevel=<loglevel>] [--replicas=<replicas>]
config invoker [--javaopts=<javaopts>] [--poolmemory=<poolmemory>] [--timeoutsrun=<timeoutsrun>] [--timeoutslogs=<timeoutslogs>] [--loglevel=<loglevel>] [--replicas=<replicas>]
config limits [--time=<time>] [--memory=<memory>] [--sequencelength=<sequencelength>] [--perminute=<perminute>] [--concurrent=<concurrent>] [--triggerperminute=<triggerperminute>] [--activation_max_payload=<activation_max_payload>]
config storage [--class=<storage_class>] [--provisioner=<storage_provisioner>]
config postgres [--failover] [--backup] [--schedule=<cron_expression>] [--replicas=<replicas>]
config minio [--s3] [--console]
config aws [--access=<access>] [--secret=<secret>] [--region=<region>] [--image=<image>] [--vm=<vm>] [--vmuser=<vmuser>] [--disk=<disk>] [--key=<key>]
config eks [--project=<project>] [--access=<access>] [--secret=<secret>] [--region=<region>] [--name=<name>] [--count=<count>] [--vm=<vm>] [--disk=<disk>] [--key=<key>] [--kubever=<kubever>]
config gcloud [--project=<project>] [--region=<region>] [--vm=<vm>] [--disk=<disk>] [--key=<key>] [--image=<image>]
config gke [--name=<name>] [--project=<project>] [--region=<region>] [--count=<count>] [--vm=<vm>] [--disk=<disk>]
config azcloud [--project=<project>] [--region=<region>] [--vm=<vm>] [--disk=<disk>] [--key=<key>] [--image=<image>]
config aks [--project=<project>] [--name=<name>] [--region=<region>] [--count=<count>] [--vm=<vm>] [--disk=<disk>] [--key=<key>]
config (status|export|reset)
config use [<n>] [--delete] [--rename=<rename>]
config minimal
Commands
config apihost configure the apihost (auto: auto assign) and enable tls
config runtime show the current runtime.json or import the <runtime-json> if provided
config enable enable OpenServerless services to install
config disable disable OpenServerless services to install
config slack configure Alert Manager over a given slack channel
config mail configure Alert Manager over a gmail account
config volumes configure the volume size distinguished in 3 categories (openwhisk couchdb & kafka, database, minio storage, alerting)
config controller configure Openwhisk enterprise controller java options
config invoker configure Openwhisk enterprise invoker options
config limits configure Openwhisk actions limits
config storage allows to customize storage persistence class and provider
config postgres allows to customize enterprise options for nuvolaris default postgres deployment
config aws configure Amazon Web Service (AWS) credentials and parameters
config gcloud configure Google Cloud credentials and parameters
config eks configure Amazon EKS Kubernetes Cluster
config azcloud configure Azure VM credentials and parameters
config aks configure Azure AKS Kubernetes Cluster
config gke configure Google Cloud GKE Kubernetes Cluster
config reset reset configuration
config status show current configuration
config export export all the variables
config use use a different kubernetes cluster among those you created
config minimal shortcut for ops config enabling only redis,mongodb,minio,cron,static,postgres
Options
--all select all services
--redis select redis
--mongodb select mongodb (FerretDB Proxy)
--minio select minio
--cron select cron
--static select static
--postgres select postgres
--tls=<email> enable tls with let's encrypt, contact email required
--access=<access> specify access key
--secret=<secret> specify secret key
--name=<name> specify name
--region=<region> specify region (AWS) location (Azure) or zone (GKE)
--count=<count> specify node count
--vm=<vm> specify vm type
--disk=<disk> specify disk size
--key=<key> specify ssh key name
--kubever=<kubever> specify kubernetes version
--delete delete the selected kubeconfig
--image=<image> specify gcp image type (default to ubuntu-minimal-2204-lts. Passing ubuntu-minimal-2204-lts-arm64 will create ARM based VM)
--prometheus select monitoring via Prometheus
--slack select alert manager module over Slack channel
--mail select alert manager module over mail channel using a gmail account
--affinity select pod affinity for multinode enterprise deployment. In such case load will be splitted between node labeled with nuvolaris-role in core or invoker
--tolerations select pod tolerations for multinode enterprise deployment.
--failover select failover support on components supporting it as postgres
--backup select automatic backup on components support it as postgres
--s3 activate s3 compatible ingress on components supporting it
--console activate a s3 console ingress on components supporting it (Currently MINIO)
--quota select quota checker module
3.4.4 - Debug
Debugging various parts of OpenServerless
Synopsis
Usage:
debug apihost
debug certs
debug config
debug images
debug ingress
debug kube
debug lb
debug log
debug route
debug runtimes
debug status
debug watch
debug operator:version
Commands
apihost show current apihost
certs show certificates
config show deployed configuration
images show current images
ingress show ingresses
kube kubernetes support subcommand prefix
lb show ingress load balancer
log show logs
route show openshift route
runtimes show runtimes
status show deployment status
watch watch nodes and pod deployment
operator:version show operator versions
3.4.5 - Ide
OpenServerless Development Utilities.
Synopsis
Usage:
ide login [<username>] [<apihost>]
ide devel [--dry-run]
ide deploy [<action>] [--dry-run]
ide undeploy [<action>] [--dry-run]
ide clean
ide setup
ide serve
ide poll
ide shell
ide kill
ide python
ide nodejs
Commands
ide login login in openserverless
ide devel activate development mode
ide deploy deploy everything or just one action
ide undeploy undeploy everything or just one action
ide clean clean the temporay files
ide setup setup the ide
ide serve serve web area
ide kill kill current devel or deploy job
ide poll poll for logs
ide shell start a shell with current env
ide python python subcommands
ide nodejs nodejs subcommands
3.4.6 - Setup
Manage installation
Synopsis
Usage:
setup devcluster [--uninstall|--status]
setup cluster [<context>] [--uninstall|--status]
setup server <server> [<user>] [--uninstall|--status]
setup status
setup uninstall
setup prereq
Commands
setup cluster deploy Apache OpenServerless in the Kubernetes cluster using the <context>, default the current
setup devcluster deploy Apache OpenServerless in a devcluster created locally
you need Docker Desktop available with at least 6G of memory assigned
setup server create a Kubernetes in server <server> and deploy Apache OpenServerless
the server must be accessible with ssh using the <user> with sudo power, default root
setup status show the status of the last installation
setup uninstall uninstall the last installation
setup prereq validate current configuration
Options
--uninstall execute an uninstall instead of an installation
--status show the status instead of an installation
Subtasks
kubernetes: prepare kubernetesnuvolaris: install nuvolarisdocker: prepare docker
3.4.7 - Util
OpenServerless Utilities
Synopsis
Usage:
util system
util update-cli
util check-operator-version <version>
util secrets
util nosecrets
util user-secrets <username>
util no-user-secrets <username>
util kubectl <args>...
util kubeconfig
util config <configjson> [--override] [--showhelp]
util upload <folder> [--batchsize=<batchsize>] [--verbose] [--clean]
Commands
- system system info (<os>-<arch> in Go format)
- update-cli update the cli downloading the binary
- check-operator-version check if you need to update the operator
- secrets generate system secrets
- nosecrets remove system secrets
- user-secrets generate user secrets for the given user
- no-user-secrets remove user secrets for the given user
- kubectl execute kubectl on current kubeconfig
- kubeconfig export OVERWRITING current kubeconfig to ~/.kube/config
- config update configuration file interactively
- upload uploads a folder to the web bucket in OpenServerless.
Options
--showhelp Show configuration tool help.
--override Override the current configuration.
--verbose Provide more details.
--clean Remove all files from the web bucket before upload.
--batchsize=<batchsize> Number of concurrent web uploads
3.5 - Tools
Available tool (embedded commands) in ops:
3.5.1 - base64
base64 utility acts as a base64 decoder when passed the --decode (or -d) flag and as a base64 encoder
otherwise. As a decoder it only accepts raw base64 input and as an encoder it does not produce the framing
lines.
Usage:
ops -base64 [options] <string>
Options
-h, --help Display this help message
-e, --encode <string> Encode a string to base64
-d, --decode <string> Decode a base64 string
Examples
Encoding
ops -base64 -e "OpenServerless is wonderful"
This will output:
T3BlblNlcnZlcmxlc3MgaXMgd29uZGVyZnVs
Decoding
ops -base64 -d "T3BlblNlcnZlcmxlc3MgaXMgd29uZGVyZnVs"
This will output:
OpenServerless is wonderful
3.5.2 - datefmt
Print date with different formats. If no time stamp or date strings are given, uses current time
Usage:
ops -datefmt [options] [arguments]
Options
-h, --help print this help info
-t, --timestamp unix timestamp to format (default: current time)
-s, --str date string to format
--if input format to use with input date string (via --str)
-f, --of output format to use (default: UnixDate)
Possible formats (they follows the standard naming of go time formats, with the addition of ‘Millisecond’ and ‘ms’):
- Layout
- ANSIC
- UnixDate
- RubyDate
- RFC822
- RFC822Z
- RFC850
- RFC1123
- RFC1123Z
- RFC3339
- RFC3339Nano
- Kitchen
- Stamp
- StampMilli
- StampMicro
- StampNano
- DateTime
- DateOnly
- TimeOnly
- Milliseconds
- ms
Example
$ ops -datefmt -f DateTime
2024-08-11 03:00:34
3.5.3 - echoif
echoif is a utility that echoes the value of <a> if the exit code of the previous command is 0,
echoes the value of <b> otherwise
Usage:
ops -echoif <a> <b>
Example
$( exit 1 ); ops -echoif "0" "1"
1
or
$( exit 0 ); ops -echoif "0" "1"
0
3.5.4 - echoifempty
echoifempty is a utility that echoes the value of <a> if <str> is empty, echoes the value of <b> otherwise.
Usage:
ops -echoifempty <str> <a> <b>
Example
ops -echoifempty "not empty string" "string is empty" "string is not empty"
3.5.5 - echoifexists
echoifexists is a utility that echoes the value of <a> if <file> exists, echoes the value of <b> otherwise.
Usage:
ops -echoifexists <file> <a> <b>
Example
ops -echoifexists "exists" "doesn't exists"
3.5.6 - empty
empty creates an empty file - returns error if it already exists.
Usage:
ops -empty <filename>
3.5.7 - executable
executable make a file executable: on Unix-like systems it will do a chmod u+x.
On Windows systems it will rename the file to .exe if needed.
Usage:
ops -executable <filename>
Example
3.5.8 - extract
Extract one single file from a .zip .tar, .tgz, .tar.gz, tar.bz2, tar.gz.
Usage:
ops -extract file.(zip|tgz|tar[.gz|.bz2|.xz]) target
Example
Extract file named single.pdf from archive.zip archive.
ops -extract archive.zip single.pdf
3.5.9 - filetype
Show extension and MIME type of a file.
Supported types are documented here
Usage:
ops -filetype [-h] [-e] [-m] FILE
Options
-h shows this help
-e show file standard extension
-m show file mime type
Examples
File Mime type
ops -filetype -m `which ops`
This will output the ops executable type:
application/x-mach-binary or application/x-executable
3.5.10 - needupdate
Check if a semver version A > semver version B.
Exits with 0 if greater, 1 otherwise.
Usage:
ops -needupdate <versionA> <versionB>
Options
-h, --help print this help info
Examples
Update is needed
ops -needupdate 1.0.1 1.0.0; echo $?
This will output:
Update is not needed
ops -needupdate 1.0.0 1.0.1; echo $?
This will output:
3.5.11 - opspath
Join a relative path to the path from where ops was executed.
This command is useful when creating custom tasks ( e.g. an ops plugin).
Usage:
ops -opspath <path>
Options:
-h, --help print this help info
Examples
You are executing in directory /home/user/my/custom/dir
This will output:
/home/user/my/custom/dir/my-file.txt
3.5.12 - random
Generate random numbers, strings and uuids
Usage:
ops -random [options]
Options
-h, --help shows this help
-u, --uuid generates a random uuid v4
--int <max> [min] generates a random non-negative integer between min and max (default min=0)
--str <len> [<characters>] generates an alphanumeric string of length <len> from the set of <characters> provided (default <characters>=a-zA-Z0-9)
Examples
Random uuid v4:
This will output something like:
5b2c45ef-7d15-4a15-84c6-29144393b621
Random integer between max and min
This will output something like:
3.5.13 - remove
Remove a file
Usage:
ops -remove <filename>
3.5.14 - rename
Rename a file
Usage:
ops -rename <source> <destination>
3.5.15 - retry
Usage:
ops -retry [options] task [task options]
Options
-h, --help Print help message
-t, --tries=# Set max retries: Default 10
-m, --max=secs Maximum time to run (set to 0 to disable): Default 60 seconds
-v, --verbose Verbose output
Example
Retry two times to get the ops action list
ops -retry -t 2 ops action list
3.5.16 - sh
sh is the mvdan shell using the ops environment.
Without args, starts an interactive shell. Otherwise execute the script specified on command line.
Usage:
ops -sh [<script>|-h|--help]
3.5.17 - urlenc
urlencode parameters using the default & separator (or a specific one using -s flag).
Optionally, encode the values retrieving them from environment variables.
Usage:
ops -urlenc [-e] [-s <string>] [parameters]
Options
-e Encode parameter values from environment variables
-h Show help
-s string Separator for concatenating the parameters (default "&")
Examples
This will output:
3.5.18 - validate
Check if a value is valid according to the given constraints.
If -e is specified, the value is retrieved from the environment variable with the given name.
Usage:
ops -validate [-e] [-m | -n | -r <regex>] <value> [<message>]
Options
-e Retrieve value from the environment variable with the given name.
-h Print this help message.
-m Check if the value is a valid email address.
-n Check if the value is a number.
-r string Check if the value matches the given regular expression.
Examples
Validate with regexp
Validate email
ops -validate -m example@gmail.com
ops -validate -r '^[a-z]+$' abc
4 - Installation
How to and where install OpenServerless
Installation
Overview
If you are in hurry and you think this guide is TL;DR (too long, don’t
read), please read at least our Quick Start
single page installation guide.
It gives you an overview of the installation process, omitting some more
advanced details. It can be enough to get you started and install
OpenServerless.
Once you want to know more, you can come back.
If you instead want the read the full documentation first, please read
on.
Steps to follow
OpenServerless can be installed in many environments, using our powerful
command line interface ops.
So you should start downloading the CLI from this
page.
Once you installed ops, before installing you need to check the
prerequisites for the installation, and satisfy
them
If the the prerequisites are OK, you can make your choices of what you
want to Configure your OpenServerless
installation.
Finally, once you have:
downloaded ops
satisfied the prerequisites
configured your installation
you can choose where to install, either:
Post Installation
After the installation, you can change later the configuration and
update the system.
Support
If you have issues, please check:
4.1 - Quick Start
Fast path to install a self-hosted OpenServerless
Quick Start
This is a quick start guide to the installation process, targeting
experienced users in a hurry.
It provides a high-level overview of the installation process, omitting
advanced of details. The missing pieces are covered in the rest of the
documentation.
Of course, if this guide is not enough and things fail, you can always
apply the rule: “if everything fails, read the manual”.
Prerequisites
Start ensuring the prerequsites are satisfied:
Download and install ops, the
OpenServerless CLI, picking version suitable for your environment.
We support 64-bit versions of recent Windows, MacOS and major Linux
distributions.
Check that ops is correctly installed: open the terminal and write:
ops -info
Configure the services you want to enable. By default,
OpenServerless will install only the serverless engine, accessible
in http with no services enabled.
If you want to enable all the services, use:
ops config enable --all
otherwise pick the services you want, among --redis, --mongodb,
--minio, --cron, --postgres. Note that --mongodb is actually
FerretDB and requires Postgres which is
implicitly also enabled. More details here.
Now, choose where to install OpenServerless.
Your options are:
locally in your workstation;
in a Linux server in your intranet
in a Linux server available on Internet
in a Kubernetes cluster in your intranet
in cloud, where you can provision a Kubernetes
cluster
Local Installation
If you have a decent workstation (with at least 16GB of memory)
running a recent 64-bit operating system, you can install
Docker Desktop and
then install OpenServerless in it. Once you have:
installed the CLI
configured the services
installed Docker Desktop
Make sure Docker Desktop its running before the next operation. Install OpenServerless and its services in Docker with just this
command:
ops setup devcluster
Once it is installed, you can proceed to read the
tutorial to learn how to code with it.
NOTE: At least 16GB of memory is ideal, but if you know what you’re
doing and can tolerate inefficiency, you can install with less using:
export PREFL_NO_MEM_CHECK=1
export PLEFL_NO_CPU_CHECK=1
Internet Server Configuration
If you have access to a server on the Internet, you will know its IP
address.
Many cloud providers also give you a DNS name usually derived by the IP
and very hard to remember such as
ec2-12-34-56-78.us-west-2.compute.amazonaws.com.
Once you got the IP address and the DNS name, you can give to your
server a bettername using a domain name
provider.
We cannot give here precise instructions as there are many DNS providers
and each has different rules to do the setup. Check with your chosen
domain name provider.
If you have this name, configure it and enable DNS with:
ops config apihost <dns-name> --tls=<email-address>
❗ IMPORTANT
Replace the <dns-name> with the actual DNS name, without using prefixes like http:// or suffixes like :443. Also,
replace ` with your actual email address.
then proceed with the server installation.
Server Installation
Once you got access to a Linux server with:
An IP address or DNS name, referred to as <server>
Passwordless access with ssh to a Linux user <user>
At least 8GB of memory and 50GB of disk space available
The user <user> has passwordless sudo rights
The firewall that allows traffic to ports 80, 443 and 6443
Without any Docker or Kubernetes installed
Without any Web server or Web application installed
then you can install OpenServerless in it.
The server can be physical or virtual. We need Kubernetes in it but the
installer takes care of installing also a flavor of Kubernetes,
K3S, courtesy of
K3Sup.
To install OpenServerless, first check you have access to the server
with:
ssh <user>@<server> sudo hostname
You should see no errors and read the internal hostname of your server.
If you do not receive errors, you can proceed to install OpenServerless
with this command:
ops setup server <server> <user>
❗ IMPORTANT
Replace in the commands <server> with the address of your server, and
<user> with the actual user to use in your server. The <server> can
be the same as <dns-name> you have configured in the previous
paragraph, if you did so, or simply the IP address of a server on your
intranet.
Now wait until the installation completes. Once it is installed, you can
proceed to read the tutorial to learn how to
code with it.
Cloud Cluster Provisioning
If you have access to a cloud provider, you can set up a Kubernetes
cluster in it. The Kubernetes cluster needs to satisfy certain
prerequisites to be able to
install OpenServerless with no issues.
We provide the support to easily configure and install a compliant
Kubernetes cluster for the following clouds:
At the end of the installation you will have available and accessible a
Kubernetes Cluster able to install OpenServerless, so proceed with a
cluster installation.
Amazon AWS
Configure and install an Amazon EKS cluster on Amazon AWS with:
ops config eks
ops cloud eks create
then install the cluster.
Azure AKS
Configure and install an Azure AKS cluster on Microsoft Azure with:
ops config aks
ops cloud aks create
then install the cluster.
Google Cloud GKE
Configure and install a Google Cloud GKE with:
ops config gke
ops cloud gke create
then install the cluster.
Cluster Install
In short, if you have access to kubernetes cluster, you can install
OpenServerless with:
ops setup cluster
For a slightly longer discussion, checking prerequisites before
installing, read on.
Prerequisites to install
If you have access to a Kubernetes cluster with:
Access to the cluster-admin role
Block storage configured as the default storage class
The nginx-ingress installed
Knowledge of the IP address of your nginx-ingress controller
you can install OpenServerless in it. You can read more details
here.
You can get this access either by provisioning a Kubernetes cluster in
cloud or getting access to it from your system
administrator.
Whatever the way you get access to your Kubernetes cluster, you will end
up with a configuration file which is usually stored in a file named
.kube/config in your home directory. This file will give access to the
Kubernetes cluster to install OpenServerless.
To install, first, verify you have actually access to the Kubernetes
cluster, by running this command:
ops debug kube info
You should get information about your cluster, something like this:
Kubernetes control plane is running at
\https://api.nuvolaris.osh.n9s.cc:6443
Now you can finally install OpenServerless with the command:
ops setup cluster
Wait until the process is complete and if there are no errors,
OpenServerless is installed and ready to go.
Once it is installed, you can proceed to read the
Tutorial to learn how to code with it.
4.2 - Download
Download OpenServerless with ops CLI
Download and Install ops
What is ops?
As you can guess it helps with operations: ops is the OPenServerless CLI.
It is a task executor on steroids.
- it embeds task, wsk and a lot of other utility commands (check with ops -help)
- automatically download and update command line tools, prerequisites and tasks
- taskfiles are organized in commands and subcommands, hierarchically and are powered by docopt
- it supports plugins
The predefined set of tasks are all you need to install and manage an OpenServerless cluster.
Download links
You can install OpenServerless using its Command Line Interface, ops.
⚠ WARNING
Since we are in a preview phase, this is not an official link approved by the Apache Software Foundation.
Quick install in Linux, MacOS and Windows with WSL or GitBash:
curl -sL bit.ly/get-ops | bash
Quick install in Windows with PowerShell
irm bit.ly/get-ops-exe | iex
After the installation
Once installed, in the first run ops will tell to update the tasks
executing:
ops -update
This command updates the OpenServerless “tasks” (its internal logic) to the
latest version. This command should be also executed frequently, as the
tasks are continuously evolving and expanding.
ops will suggest when to update them (at least once a day).
You normally just need to update the tasks but sometimes you also need
to update ops itself. The system will detect when it is the case and
tell you what to do.
Where to find more details:
For more details, please visit the Github page of Openserverless Cli
4.3 - Prerequisites
Prerequisites to install OpenServerless
This page lists the prerequisites to install OpenServerless in various
environments.
You can install OpenServerless:
for development in a single node environment,
either in your local machine or in a Linux server.
for production, in a multi node environment
provided by a Kubernetes cluster.
Single Node development installation
For development purposes, you can install a single node
OpenServerless deployment in the following environments as soon as the
following requirements are satisfied:
Our installer can automatically install a Kubernetes environment, using
K3S, but if you prefer you can install a single-node
Kubernetes instance by yourself.
If you choose to install Kubernetes on your server, we provide support
for:
Multi Node production installation
For production purposes, you need a multi-node Kubernetes cluster
that satisfies those requirements,
accessible with its kubeconfig file.
If you have such a cluster, you can install
OpenServerless in a Kubernetes cluster
If you do not have a cluster and you need to setup one, we provide
support for provisioning a suitable cluster that satisfied our
requirements for the following Kubernetes environments:
Once you have a suitable Kubernetes cluster, you can proceed
installing OpenServerless.
4.3.1 - Local Docker
Install OpenServerless with Docker locally
Prerequisites to install OpenServerless with Docker
You can install OpenServerless on your local machine using Docker. This
page lists the prerequisits.
First and before all you need a computer with at least 16 GB of memory
and 30GB of available space.
❗ IMPORTANT
8GB are definitely not enough to run OpenServerless on your local
machine.
Furthermore, you need to install Docker. Let’s see the which one to
install and configure if you have:
- Windows
- MacOS
- Linux
Windows
You require the 64 bit edition in Intel Architecture of a recent version
of Windows (at least version 10). The installer ops does not run on 32
bit versions nor in the ARM architecture.
Download and install Docker
Desktop for Windows.
Once installed, you can proceed
configuring OpenServerless for the
installation.
MacOS
You require a recent version of MacOS (at least version 11.xb BigSur).
The installer ops is available both for Intel and ARM.
Download and install Docker
Desktop for MacOS.
Since MacOS uses a virtual machine for Docker with a constrained memory.
you also need also to reserve at least 8GB.
❗ IMPORTANT
On MacOS, Docker defaults to 2GB memoery and they are definitely not enough to run
OpenServerless on your local machine.
Instructions to increase the memory reserved to Docker Desktopo on
MacOS:
Once installed, you can proceed
configuring OpenServerless for the installation.
Linux
Docker Desktop is available also on Linux, however we advice to install
instead the Server Docker
Engine
On Linux, the Docker Engine for the server does not run in a virtual
machine, so it is faster and uses less memory.
Once installed, you can proceed
configuring OpenServerless for the installation.
4.3.2 - Linux Server
Install OpenServerless in a Linux server
Prerequisites to install OpenServerless in a Linux server
You can install OpenServerless on any server either in your intranet or
on in Internet running a Linux distribution, with the following
requirements:
You know the IP address or DNS name of the server on Internet or
in your Intranet.
The server requires at least 8GB of memory and 30GB of disk space
available.
It should be running a Linux distribution supported by
K3S.
You must open the firewall to access ports 80, 443 and 6443 (for
K3S) or 16443 (for MicroK8S) from your machine.
You have to install a
public ssh key to access it
without a password.
You have to configure
sudo to execute root
commands without a password.
You can:
Once you have such a server you can optionally (it is not required)
install K3S or
MicroK8S in it.
Once you have configured you server, you can proceed
configuring OpenServerless for the installation.
4.3.2.1 - SSH and Sudo
General prerequisites to install OpenServerless
If you have access to a generic Linux server, to be able to install
OpenServerless it needs to:
be accessible without a password with ssh
be able to run root commands without a password with sudo
open the ports 80, 443 and 6443 or 16443
If your server does not already satisfy those requirements, read below
for information how to create a sshkey,
configure sudo and open the firewall
Installing a public SSH key
To connect to a server without a password using openssh (used by the
installer), you need a couple of files called ssh keys.
You can generate them on the command line using this command:
ssh-keygen
It will create a couple of files, typically called:
~/.ssh/id_rsa
~/.ssh/id_rsa.pub
where ~ is your home directory.
You have to keep secret the id_rsa file because it is the private key
and contains the information to identify you uniquely. Think to is as
your password.
You can copy the id_rsa.pub in the server or even share it publicly,
as it is the public key. Think to it as your login name, and adding this
file to the server adds you to the users who can login into it.
Once you have generated the public key, access your server, then edit
the file ~/.ssh/authorized_keys adding the public key to it.
It is just one line, contained in the id_rsa.pub file.
Create the file if it does not exist. Append the line to the file (as a
single line) if it already exists. Do not remove other lines if you do
not want to remove access to other users.
Configure Sudo
You normally access Linux servers using a user that is not root
(the system administrator with unlimited power on the system).
Depending on the system, the user to use to access be ubuntu,
ec2-user, admin or something else entirely. However if you have
access to the server, the information of which user to use should have
been provided, including a way to access to the root user.
You need to give this user the right to execute commands as root
without a password, and you do this by configuring the command sudo.
You usually have either access to root with the su command, or you can
execute sudo with a password.
Type either su or sudo bash to become root and edit the file
/etc/sudoers adding the following line:
<user> ALL=(ALL) NOPASSWD:ALL
where <user> is the user you use to log into the system.
Open the firewall
You need to open the following ports in the firewall of the server:
For information on how to open the firewall, please consult the
documentation of your cloud provider or contact your system
administrator, as there are no common procedures and they depends on the
cloud provider.
4.3.2.2 - Server on AWS
Prerequisites to install OpenServerless in AWS
Provision a Linux server in Amazon Web Services
You can provision a server suitable to install OpenServerless in cloud
provider Amazon Web Services
ops as follows:
install aws, the AWS CLI
get Access and Secret Key
configure AWS
provision a server
retrieve the ip address to configure a DNS name
Once you have a Linux server up and running you can proceed
configuring and
installing OpenServerless.
Installing the AWS CLI
Our cli ops uses under the hood the AWS CLI version
2,
so you need to dowload and install it following those
instructions.
Once installed, ensure it is available on the terminal executing the
following command:
aws --version
you should receive something like this:
aws-cli/2.9.4 Python/3.9.11 Linux/5.19.0-1025-aws exe/x86_64.ubuntu.22 prompt/off
Ensure the version is at least 2.
Getting the Access and Secret key
Next step is to retrieve credentials, in the form of an access key and a
secret key.
So you need to:
You will end up with a couple of string as follows:
Sample AWS Access Key ID: AKIAIOSFODNN7EXAMPLE Sample AWS Secret Access
Key: wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY
Take note of them as you need them for configuring out CLI.
Before you can provision a Linux server you have to configure AWS typing
the command:
ops config aws
The system will then ask the following questions:
*** Please, specify AWS Access Id and press enter.
AKIAIOSFODNN7EXAMPLE
*** Please, specify AWS Secret Key and press enter.
wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY
*** Please, specify AWS Region to use and press enter.
To get a list of valid values use:
aws ec2 describe-regions --output table
Just press enter for default [us-east-1]:
*** Please, specify AWS public SSH key and press enter.
If you already have a public SSH key in AWS, provide its name here.
If you do not have it, generate a key pair with the following command:
ssh-keygen
The public key defaults to ~/.ssh/id_rsa.pub and you can import with:
aws ec2 import-key-pair --key-name nuvolaris-key --public-key-material --region=<your-region> fileb://~/.ssh/id_rsa.pub
Just press enter for default [devkit-74s]:
*** Please, specify AWS Image to use for VMs and press enter.
The suggested image is an Ubuntu 22 valid only for us-east-1
Please check AWS website for alternative images in other zones
Just press enter for default [ami-052efd3df9dad4825]:
*** Please, specify AWS Default user for image to use for VMs and press enter.
Default user to access the selected image.
Just press enter for default [ubuntu]:
*** Please, specify AWS Instance type to use for VMs and press enter.
The suggested instance type has 8GB and 2vcp
To get a list of valid values, use:
aws ec2 describe-instance-types --query 'InstanceTypes[].InstanceType' --output table
Just press enter for default [t3a.large]:
*** Please, specify AWS Disk Size to use for VMs and press enter.
Just press enter for default [100]:
Provision a server
You can provision one or more servers using ops. The servers will use
the parameters you have just configured.
You can create a new server with:
ops cloud aws vm-create <server-name>
❗ IMPORTANT
Replace <server-name> with a name you choose, for example
ops-server
The command will create a new server in AWS with the parameters you
specified in configuration.
You can also:
list servers you created with ops cloud aws vm-list
delete a server you created and you do not need anymore with
ops cloud aws vm-delete <server-name>
Retrieve IP
The server will be provisioned with an IP address assigned by AWS.
You can read the IP address of your server with
ops cloud aws vm-getip <server-name>
You need this IP when configuring a DNS name for
the server.
4.3.2.3 - Server on Azure
Prerequisites to install OpenServerless in Azure
You can provision a server suitable to install OpenServerless in cloud
provider Azure
ops as follows:
install az, the Azure CLI
get Access and Secret Key
configure Azure
provision a server
retrieve the ip address to configure a DNS name
Once you have a Linux server up and running you can proceed
configuring and
installing OpenServerless.
Installing the Azure CLI
Our cli ops uses under the hood the az,
command so you need to dowload and install it following those
instructions.
Once installed, ensure it is available on the terminal executing the
following command:
az version
you should receive something like this:
{
"azure-cli": "2.64.0",
"azure-cli-core": "2.64.0",
"azure-cli-telemetry": "1.1.0",
"extensions": {
"ssh": "2.0.5"
}
}
Ensure the version is at least 2.64.0
Connect a subscription
Next step is to connect az to a valid Azure subscription. Azure
supports several authentication methods: check
which one you prefer.
The easiest is the one described in Sign in interactively:
az login
This will open a browser and you will asked to login to you azure account. Once logged in, the az command will be
automatically connected to the choosen subscription.
To check if the az command is properly connected to your subscription, check the output of this command:
$ az account list --query "[].{subscriptionId: id, name: name, user: user.name}" --output table
SubscriptionId Name User
------------------------------------ --------------------------- -------------------------
xxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxx Microsoft Azure Sponsorship openserverless@apache.org
Before you can provision a Linux server you have to configure Openserverless for Azure typing
the command:
ops config azcloud
The system will then ask the following questions:
*** Please, specify Azure Project Id and press enter.
Azure Project Id: openserverless-k3s
*** Please, specify Azure Zone and press enter.
To get a list of valid values use:
az account list-locations -o table
Just press enter for default [eastus]:
Azure Zone:
*** Please, specify Azure virtual machine type and press enter.
To get a list of valid values, use:
az vm list-sizes --location <location> -o table
where <location> is your current location.
Just press enter for default [Standard_B4ms]:
Azure virtual machine type:
*** Please, specify Azure vm disk size in gigabyte and press enter.
Just press enter for default [50]:
Azure vm disk size in gigabyte:
*** Please, specify Azure Cloud public SSH key and press enter.
If you already have a public SSH key provide its path here. If you do not have it, generate a key pair with the following command:
ssh-keygen
The public key defaults to ~/.ssh/id_rsa.pub.
Just press enter for default [~/.ssh/id_rsa.pub]:
Azure Cloud public SSH key:
*** Please, specify Azure Cloud VM image and press enter.
Just press enter for default [Ubuntu2204]:
Azure Cloud VM image:
Provision a server
You can provision one or more servers using ops. The servers will use
the parameters you have just configured.
You can create a new server with:
ops cloud azcloud vm-create <server-name>
❗ IMPORTANT
Replace <server-name> with a name you choose, for example
ops-server
The command will create a new server in Azure Cloud with the parameters
you specified in configuration.
You can also:
list servers you created with ops cloud azcloud vm-list
delete a server you created and you do not need anymore with
ops cloud azcloud vm-delete <server-name>
Retrieve IP
The server will be provisioned with an IP address assigned by Azure
Cloud.
You can read the IP address of your server with
ops cloud azcloud vm-getip <server-name>
You need this IP when configuring a DNS name for
the server.
4.3.2.4 - Install K3S
Prerequisites to install OpenServerless in K3S
Install K3S in a server
You can install OpenServerless as described
here, and you do not need to
install any Kubernetes in it, as it is installed as part of the
procedure. In this case it installs K3S.
Or you can install K3S in advance, and then proceed
configuring and then installing
OpenServerless as in any other Kubernetes
cluster.
Installing K3S in a server
Before installing ensure you have satified the
prerequisites, most notably:
you know the IP address or DNS name
your server operating system satisfies the K3S
requirements
you have passwordless access with ssh
you have a user with passwordless sudo rights
you have opened the port 6443 in the firewall
Then you can use the following subcommand to install in the server:
ops cloud k3s create <server> [<username>]
where <server> is the IP address or DNS name to access the server,
and the optional <username> is the user you use to access the server:
if is not specified, the root username will be used.
Those pieces of information should have been provided when provisioning
the server.
❗ IMPORTANT
If you installed a Kubernetes cluster in the server this way, you should
proceed installing OpenServerless as in
a Kubernetes cluster, not
as a server.
The installation retrieves also a Kubernetes configuration file, so you
can proceed to installing it without any other step involved.
Additional Commands
In addition to create the following subcommands are also available:
ops cloud k3s delete <server> [<username>]:
uninstall K3S from the server
ops cloud k3s kubeconfig <server> [<username>]:
retrieve the kubeconfig from the K3S server
ops cloud k3s info: some information about the server
ops cloud k3s status: status of the server
4.3.2.5 - Install MicroK8S
Prerequisites to install OpenServerless in K8S
Install MicroK8S in a server
You can install OpenServerless as
described here and you do not need to
install any Kubernetes in it, as it is installed as part of the procedure. In
this case it installs K3S.
But you can install MicroK8S instead, if you
prefer. Check here for informations about MicroK8S.
If you install MicroK8S in your server, you can then proceed
configuring and then installing OpenServerless
as in any other Kubernetes cluster.
Installing MicroK8S in a server
Before installing ensure you have
satisfied the prerequisites, most notably:
you know the IP address or DNS name
you have passwordless access with ssh
you have an user with passwordless sudo rights
you have opened the port 16443 in the firewall
Furthermore, since MicroK8S is installed using snap, you also need to
install snap.
💡 NOTE
While snap is available for many linux distributions, it is typically
pre-installed and well supported in in Ubuntu and its derivatives. So we
recommend MicroK8S only if you are actually using an Ubuntu-like Linux
distribution.
If you system is suitable to run MicroK8S you can use the following
subcommand to install in the server:
ops cloud mk8s create SERVER=<server> USERNAME=<username>
where <server> is IP address or DNS name to access the server, and
<username> is the user you use to access the server.
Those informations should have been provided when provisioning the
server.
❗ IMPORTANT
If you installed a Kubernetes cluster in the server in this way, you
should proceed installing OpenServerless as in
a Kubernetes cluster, not as a server.
The installation retrieves also a kubernets configuration file so you
can proceed to installing it without any other step involved.
Additional Commands
In addition to create you have available also the following
subcommands:
ops cloud mk8s delete SERVER=<server> USERNAME=<username>:
uninstall K3S from the server
ops cloud mk8s kubeconfig SERVER=<server> USERNAME=<username>:
retrieve the kubeconfig from the MicroK8S server
ops cloud mk8s info: informations about the server
ops cloud mk8s status: status of the server
4.3.3 - Kubernetes Cluster
Install OpenServerless in a Kubernetes cluster
Prerequisites to install OpenServerless in a Kubernetes cluster
You can install OpenServerless in any Kubernetes cluster which
satisfy some requirements.
Kubernetes clusters are available pre-built from a variety of cloud
providers. We provide with our ops tool the commands to install a
Kubernetes cluster ready for OpenServerless in the following
environments:
You can also provision a suitable cluster by yourself, in any cloud or
on premises, ensuring the prerequites are satisfied.
Once provisioned, you will receive a configuration file to access the
cluster, called kubeconfig.
This file should be placed in ~/.kube/config to give access to the
cluster
If you have this file, you can check if you have access to the cluster
with the command:
ops debug kube info
You should see something like this:
Kubernetes control plane is running at https://xxxxxx.yyy.us-east-1.eks.amazonaws.com
Once you have got access to the Kubernetes cluster, either installing
one with out commands or provisioning one by yourself, you can proceed
configuring the installation and then
installing OpenServerless in the
cluster.
4.3.3.1 - Amazon EKS
Prerequisites for Amazon EKS
Prerequisites to install OpenServerless in an Amazon EKS Cluster
Amazon EKS is a pre-built Kubernetes
cluster offered by the cloud provider Amazon Web
Services.
You can create an EKS Cluster in Amazon AWS for installing using
OpenServerless using ops as follows:
install aws, the AWS CLI
get Access and Secret Key
configure EKS
provision EKS
optionally, retrieve the load balancer address to
configure a DNS name
Once you have EKS up and running you can proceed
configuring and installing
OpenServerless.
Installing the AWS CLI
Our cli ops uses under the hood the AWS CLI version
2,
so you need to dowload and install it following those
instructions.
Once installed, ensure it is available on the terminal executing the
following command:
aws --version
you should receive something like this:
aws-cli/2.9.4 Python/3.9.11 Linux/5.19.0-1025-aws exe/x86_64.ubuntu.22 prompt/off
Ensure the version is at least 2.
Getting the Access and Secret key
Next step is to retrieve credentials, in the form of an access key and a
secret key.
So you need to: * access the AWS console following those
instructions
create an access key and secret key, * give to the credentials the
minimum required permissions as described
here to build an EKS
cluster.
You will end up with a couple of string as follows:
Sample AWS Access Key ID: AKIAIOSFODNN7EXAMPLE Sample AWS Secret Access
Key: wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY
Take note of them as you need them for configuring out CLI.
Once you have the access and secret key you can configure EKS with the
command ops config eks answering to all the questions, as in the
following example:
$ ops config eks
*** Please, specify AWS Access Id and press enter.
AKIAIOSFODNN7EXAMPLE
*** Please, specify AWS Secret Key and press enter.
wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY
*** Please, specify AWS Region to use and press enter.
To get a list of valid values use:
aws ec2 describe-regions --output table
Just press enter for default [us-east-2]:
*** Please, specify AWS public SSH key and press enter.
If you already have a public SSH key in AWS, provide its name here.
If you do not have it, generate a key pair with the following command:
ssh-keygen
The public key defaults to ~/.ssh/id_rsa.pub and you can import with:
aws ec2 import-key-pair --key-name nuvolaris-key --public-key-material --region=<your-region> fileb://~/.ssh/id_rsa.pub
Just press enter for default [nuvolaris-key]:
*** Please, specify EKS Name for Cluster and Node Group and press enter.
Just press enter for default [nuvolaris]:
*** Please, specify EKS region and press enter.
To get a list of valid values use:
aws ec2 describe-regions --output table
Just press enter for default [us-east-1]:
*** Please, specify EKS number of worker nodes and press enter.
Just press enter for default [3]:
*** Please, specify EKS virtual machine type and press enter.
To get a list of valid values, use:
aws ec2 describe-instance-types --query 'InstanceTypes[].InstanceType' --output table
Just press enter for default [m5.xlarge]:
*** Please, specify EKS disk size in gigabyte and press enter.
Just press enter for default [50]:
*** Please, specify EKS Kubernetes Version and press enter.
Just press enter for default [1.25]:
Provisioning Amazon EKS
Once you have configured it, you can create the EKS cluster with the
command:
ops cloud eks create
It will take around 20 minutes to be ready. Please be patient.
At the end of the process, you will have access directly to the created
Kubernetes cluster for installation.
Retrieving the Load Balancer DNS name
Once the cluster is up and running, you need to retrieve the DNS name of
the load balancer.
You can read this with the command:
ops cloud eks lb
Take note of the result as it is required for
configuring a dns name for your cluster.
Additional Commands
You can delete the created cluster with: ops cloud eks delete
You can extract again the cluster configuration, if you lose it,
reconfiguring the cluster and then using the command
ops cloud eks kubeconfig.
4.3.3.2 - Azure AKS
Prerequisites for Azure AKS
Prerequisites to install OpenServerless in an Azure AKS Cluster
Azure AKS is a pre-built Kubernetes
cluster offered by the cloud provider Microsoft Azure.
You can create an AKS Cluster in Microsoft Azure for installing using
OpenServerless using ops as follows:
install az, the Azure CLI
configure AKS
provision AKS
optionally, retrieve the load balancer address to
configure a DNS name
Once you have AKS up and running you can proceed
configuring and installing
OpenServerless.
Installing the Azure CLI
Our CLI ops uses under the hood the Azure
CLI, so you need to
dowload and install it
following those instructions.
Once installed, ensure it is available on the terminal executing the
following command:
az version
you should receive something like this:
{
"azure-cli": "2.51.0",
"azure-cli-core": "2.51.0",
"azure-cli-telemetry": "1.1.0",
"extensions": {}
}
Before provisioning your AKS cluster you need to configure AKS with the
command ops config aks answering to all the questions, as in the
following example:
$ ops config aks
*** Please, specify AKS Name for Cluster and Resource Group and press enter.
Just press enter for default [nuvolaris]:
*** Please, specify AKS number of worker nodes and press enter.
Just press enter for default [3]:
*** Please, specify AKS location and press enter.
To get a list of valid values use:
az account list-locations -o table
Just press enter for default [eastus]:
*** Please, specify AKS virtual machine type and press enter.
To get a list of valid values use:
az vm list-sizes --location <location> -o table
where <location> is your current location.
Just press enter for default [Standard_B4ms]:
*** Please, specify AKS disk size in gigabyte and press enter.
Just press enter for default [50]:
*** Please, specify AKS public SSH key in AWS and press enter.
If you already have a public SSH key provide its path here. If you do not have it, generate a key pair with the following command:
ssh-keygen
The public key defaults to ~/.ssh/id_rsa.pub.
Just press enter for default [~/.ssh/id_rsa.pub]:
Provisioning Azure AKS
Once you have configured it, you can create the AKS cluster with the
command:
ops cloud aks create
It will take around 10 minutes to be ready. Please be patient.
At the end of the process, you will have access directly to the created
Kubernetes cluster for installation.
Retrieving the Load Balancer DNS name
Once the cluster is up and running, you need to retrieve the DNS name of
the load balancer.
You can read this with the command:
ops cloud aks lb
Take note of the result as it is required for
configuring a dns name for your cluster.
Additional Commands
You can delete the created cluster with: ops cloud aks delete
You can extract again the cluster configuration, if you lose it,
reconfiguring the cluster and then using the command
nuv cloud aks kubeconfig.
4.3.3.3 - Generic Kubernetes
Prerequisites for all Kubernetes
Kubernetes Cluster requirements
OpenServerless installs in any Kubernetes cluster which satisfies the
following requirements:
cluster-admin access
at least 3 worker nodes with 4GB of memory each
support for block storage configured as default storage class
support for LoadBalancer services
the nginx ingress
already installed
the cert manager already installed
Once you have such a cluster, you need to retrieve the IP address of the
Load Balancer associated with the Nginx Ingress. In the default
installation, it is installed in the namespace nginx-ingress and it is
called ingress-nginx-controller.
In the default installation you can read the IP address with the
following command:
kubectl -n ingress-nginx get svc ingress-nginx-controller
If you have installed it in some other namespace or with another name,
change the command accordingly.
The result should be something like this:
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
ingress-nginx-controller LoadBalancer 10.0.9.99 20.62.156.19 80:30898/TCP,443:31451/TCP 4d1h
Take note of the value under EXTERNAL-IP as you need it in the next
step of installation, configuring DNS.
4.4 - Configure OpenServerless
Configuring OpenServerless Installation
This section guides configuring the OpenServerless installation.
Note that you can also skip this configuration, and install
OpenServerless without any configuration.
Once you configure the installation, you can proceed to
Install OpenServerless.
You can then reconfigure the system later.
Minimal Configuration
Without any configuration, you get a minimal OpenServerless:
You can:
4.4.1 - DNS and SSL
Configuring DNS and SSL
Configuring DNS and SSL
You can use OpenServerless as just as a serverless engine, and use the
default IP or DNS provided when provisioned your server or cluster. If
you do so, only http is avaialble, and it is not secure.
If you want your server or cluster is available with a well-known
internet name, you can associate the IP address or the “ugly”
default DNS name of serveres or clusters to a DNS name of your choice,
to use it also to publish the static front-end of your server.
Furthermore, once you decided for a DNS name for your server, you can
enable the provisioning of an SSL certificate so you server will be
accessible with https.
In order to configure the DNS and the SSL the steps are:
retrieve the IP address or the the DNS name of your
server or cluster
register a DNS name of your choice with your
registration name provider
configure OpenServerless so he knows of the DNS and
SSL and can use it
Retrieving the IP address or the DNS name
If OpenServerless is installed in your local machine with Docker, cannot
configure any DNS nor SSL, so you can proceed configuring the
services.
If OpenServerless is installed in a single server, after you
satisfied the server prerequisites you will
know the IP address or DNS name of you server.
If OpenServerless is installed in a Kubernetes cluster, after you
satisfied the server cluster prerequisites
you know either the IP address or the DNS name of the load balancer.
Register a DNS name or wildcard
Using the address of your server or cluster, you need either to
configure a DNS name your already own or contact a domain name
registrar to register a
new DNS name dedicated to your server or cluster.
You need at least one DNS name in a domain you control, for example
nuvolaris.example.com that points to you IP or address.
Note that:
If you have an IP address to your load balancer you need to
configure an A record mapping nuvolaris.example.com to the IP
address of your server.
If you have a DNS name to your load balancer, you need to configure
a CNAME record mapping nuvolaris.example.com to the DNS name of
your server.
💡 NOTE
If you are registering a dedicated domain name for your cluster, you are
advised to register wildcard name (*) for every domain name in
example.com will resolve to your server.
Registering a wildcard is required to get a different website for for
multiple users.
Once you registrered a single DNS (for example openserverless.example.com)
or a wildcard DNS name (for example *.example.com) you can communicate
to the installer what is the main DNS name of your cluster or server, as
it is not able to detect it automatically. We call this the <apihost>
💡 NOTE
If you have registered a single DNS name, like openserverless.example.com
use this name as <apihost>.
If you have registered a wildcard DNS name, you have to choose a DNS
name to be used as <apihost>.
We recommended you use a name starting with api since to avoid
clashes, user and domain names starting with api are reserved. So if
you have a *.example.com wildcard DNS available, use api.example.com
as your <apihost>
Once you decided what is your API host, you can configure this as
follows:
ops config apihost <apihost>
This configuration will assign a well know DNS name as access point of
your OpenServerless cluster. However note it does NOT enable SSL.
Accessing to your cluster will happen using HTTP.
Since requests contain sensitive information like security keys, this is
highly insecure. You hence do this only for development or testing
but never for production.
Once you have a DNS name, enabling https is pretty easy, since we can
do it automatically using the free service Let's Encrypt. We have
however to provide a valid email address <email>.
Once you know your <apihost> and the <email> to receive
communications from Let’s Encrypt (mostly, when a domain name is
invalidated and needs to be renewed), you can configure your apihost and
enable SSL as follows:
ops config apihost <apihost> --tls=<email>
Of course, replace the <apihost> with the actual DNS name you
registered, and <email> with your email address
4.4.2 - Services
Configure OpenServerless services
Configuring OpenServerless services
After you satisfied the prerequisites and
before you actually install OpenServerless, you
have to select which services you want to install:
Static, publishing of static assets
Redis, a storage service
MinIO an object storage service
Postgres a relational SQL database
FerretDB A MongoDB-compatible adapter for Postgres
You can enable all the services with:
ops config enable --all
or disable all of them with:
ops config disable --all
Or select the services you want, as follows.
Static Asset Publishing
The static service allows you to publish static asset.
💡 NOTE
you need to setup a a wildcard DNS name
to be able to access them from Internet.
You can enable the Static service with:
ops config enable --static
and disable it with:
ops config disable --static
Redis
Redis, is a fast, in-memory key-value store, usually
used as cache, but also in some cases as a (non-relational) database.
Enable REDIS:
ops config enable --redis
Disable REDIS:
ops config disable --redis
MinIO
MinIO is an object storage service
Enable minio:
ops config enable --minio
Disable minio:
ops config disable --minio
Postgres
Postgres is an SQL (relational) database.
Enable postgres:
ops config enable --postgres
Disable postgres:
ops config disable --postgres
FerretDB
FerretDB is a MongoDB-compatible adapter for
Postgres. It created a document-oriented database service on top of
Postgres.
💡 NOTE
Since FerretDB uses Postgres as its storage, if you enable it, also the
service Postgresql will be enabled as it is required.
Enable MongoDB api with FerretDB:
ops config enable --mongodb
Disable MongoDB api with FerretDB:
ops config disable --mongodb
4.5 - Install OpenServerless
Installation Overview
This page provides an overview of the installation process.
Before installation
Please ensure you have:
Core Installation
Once you have completed the preparation steps, you can proceed with:
💡 NOTE
The install process will notify nuvolaris creators with the type of installation (for example: clustered or server installation), no other info will be submitted. If you want to disable the notification, you can execute the following command before the setup command:
ops -config DO_NOT_NOTIFY_NUVOLARIS=1
Post installation
After the installation, you can consult the development guide
for informations how to reconfigure and update the system.
Support
If something goes wrong, you can check:
4.5.1 - Docker
Install OpenServerless on a local machine
Local Docker installation
This page describes how to install OpenServerless on your local machine. The
services are limited and not accessible from the outside so it is an
installation useful only for development purposes.
Prerequisites
Before installing, you need to:
💡 NOTE
The static service works perfectly for the default namespace nuvolaris which is linking the http://localhost to the
nuvolaris web bucket. With this setup adding new users will add an ingress with host set to
namespace.localhost, that in theory could also work if the host file of the development machine is configured
to resolve it to the 127.0.0.1 ip address.
⚠ WARNING
You cannot have https in a local installation.
If you enable it, the configuration will be ignored.
Installation
Run the commands:
- Minimal configuration
Behind the scene, this command will write a cluster configuration file called ~/.ops/config.json activating these
services: static, redis, postgres, ferretdb, minio, cron constituting the common baseline for development
tasks.
- Setup the cluster
and wait until the command terminates.
Click here to see a log sample of the setup
ops setup devcluster
Creating cluster "nuvolaris" ...
✓ Ensuring node image (kindest/node:v1.25.3) 🖼
✓ Preparing nodes 📦 📦
✓ Writing configuration 📜
✓ Starting control-plane 🕹️
✓ Installing CNI 🔌
✓ Installing StorageClass 💾
✓ Joining worker nodes 🚜
✓ Waiting ≤ 1m0s for control-plane = Ready ⏳
• Ready after 1s 💚
Set kubectl context to "kind-nuvolaris"
You can now use your cluster with:
kubectl cluster-info --context kind-nuvolaris --kubeconfig /Users/bruno/.ops/tmp/kubeconfig
Thanks for using kind!
[...continue]
💡 NOTE
The log will continue because, after kind is up and running, OpenServerless namespace and relative services are
installed inside.
It will take some minute to complete, so be patient.
Troubleshooting
Usually the setup completes without errors.
However, if ops is unable to complete the setup, you may see this message at the end:
ops: Failed to run task "create": exit status 1
task execution error: ops: Failed to run task "create": exit status 1
ops: Failed to run task "devcluster": exit status 1
task execution error: ops: Failed to run task "devcluster": exit status 1
If this is your case, try to perform a uninstall / reinstall:
ops setup cluster --uninstall
ops config reset
ops config minimal
ops setup devcluster
If this will not solve, please contact the community.
Post install
Check the tutorial to learn how to use it.
Uninstall
To uninstall you may:
Uninstall devcluster
This will actually remove the ops namespace and all the services from kind.
Useful to re-try an installation when something gone wrong.
ops setup cluster --uninstall
ops config reset
Remove devcluster
This will actually remove the nodes from kind:
ops setup devcluster --uninstall
4.5.2 - Linux Server
Install on a Linux Server
Server Installation
This page describes how to install OpenServerless on a Linux server
accessible with SSH.
This is a single node installation, so it is advisable only for
development purposes.
Prerequisites
Before installing, you need to:
install the OpenServerless CLI ops;
provision a server running a Linux operating system,
either a virtual machine or a physical server, and you know its IP address
or DNS name;
configure it to have passwordless ssh access and sudo rights;
open the firewall to have access to ports 80, 443 and 6443 or 16443
from your client machine;
configure the DNS name for the server and choose
the services you want to enable;
Installation
If the prerequisites are satisfied, execute the dommand:
ops setup server <server> <user>
❗ IMPORTANT
Replace in the command before <server> with the IP address or DNS name
used to access the server, and <user> with the username you have to
use to access the server
Wait until the command completes and you will have OpenServerless up and
running.
Post Install
ops setup server <server> <user> --uninstall
4.5.3 - Kubernetes cluster
Install OpenServerless on a Kubernetes Cluster
Cluster Installation
This section describes how to install OpenServerless on a Kubernetes Cluster
Prerequisites
Before installing, you need to:
Installation
If you have a Kubernetes cluster directly accessible with its
configuration, or you provisioned a cluster in some cloud using ops
embedded tools, you just need to type:
ops setup cluster
Sometimes the kubeconfig includes access to multiple Kubernetes
instances, each one identified by a different <context> name. You can
install the OpenServerless cluster in a specified <context> with:
ops setup cluster <context>
Post Install
ops setup cluster --uninstall
4.6 - Troubleshooting
How to diagnose and solve issues
Debug
This document gives you hints for diagnostics and solving issues, using
the (hidden) subcommand debug.
Note it is technical and assumes you have some knowledge of how
Kubernetes operates.
Watching
While installing, you can watch the installation (opening another
terminal) with the command:
ops debug watch
Check that no pods will go in error while deploying.
Configuration
You can inspect the configuration with the ops debug subcommand
API host: ops debug apihost
Static Configuration: ops debug config.
Current Status: ops debug status
Runtimes: ops debug runtimes
Load Balancer: ops debug lb
Images: ops debug images
Logs
You can inspect logs with ops debug log subcommand. Logs you can show:
operator: ops debug log operator (continuously:
ops debug log foperator)
controller: ops debug log controller (continuously:
ops debug log fcontroller)
database: ops debug log couchdb (continuously:
ops debug log fcouchdb)
certificate manager: ops debug log certman
(continuously: ops debug log fcertmap)
Kubernetes
You can detect which Kubernetes are you using with:
ops debug detect
You can then inspect Kubernetes objects with:
namespaces: ops debug kube ns
nodes: ops debug kube nodes
pod: ops debug kube pod
services: ops debug kube svc
users: ops debug kube users
You can enter a pod by name (use kube pod to find the name) with:
ops debug kube exec P=<pod-name>
Kubeconfig
Usually, ops uses a hidden kubeconfig so does not override your
Kubernetes configuration.
If you want to go more in-depth and you are knowledgeable of Kubernetes,
you can export the kubeconfig with ops debug export F=<file>.
You can overwrite your kubeconfig (be aware there is no backup) with
ops debug export F=-.